


























New on LowEndTalk? Please Register and read our Community Rules.
All new Registrations are manually reviewed and approved, so a short delay after registration may occur before your account becomes active.
All new Registrations are manually reviewed and approved, so a short delay after registration may occur before your account becomes active.

Comments
One additional note, a feature request. Unless I'm missing something, the onboarding process seems pretty manual. A universal installer that dumps machines in to the account based on their hostname and then we can go back in and put a description if we need to.
Thanks you for the feedback, really appreciate it")
At the same price there is no competitors providing the same amount of data collection right now (Proxmox, KVM/QEMU, Docker, Fail2Ban, etc).
Yeah, it's pretty manual for now indeed. Could you tell me more about how you think it could work best for you ?
How I interpret their message (and because it's the way I think would make it easier and probably not unrealistically hard to implement) is that instead of getting one command per machine give one link with an UUID that is connected to the user account instead of the already created node.
The backend would then create a new node based on the hostname (or some other parameter that would make sense) so that after executing said command you would go to the control panel where a "blank" node has been created and is ready to be configured.
Makes sense, I will work on something like this 👍
FYI, agent version 1.5.0 has been released and allow you to see all packages vulnerabilities across your nodes:
This is Pro plan feature but if you're interested by giving it a try, just ping me!
Very minor detail and maybe it's just me and my ocd talking, but on website under comparison with HetrixTools, it says "Metric collection intervals" and under FiveNines it says "up to five seconds". Shouldn't that say "down to five seconds"? Up to five seconds in my mind means everything below 5 seconds, not the other way around.
I'm not a nativ English speaker so it could be just me, open for discussion.
You're definitely right, fixed!
@ItsGermy @zejjnt I just released the bulk install feature (available on all paid plans):
I just received this email about an outage in the service due to hardware failure and I just came here to say that this is how communication should be done. Providers, watch and learn!
No excuses, just the facts, and in a timely fashion. What happened, what was affected, and what they are doing to make sure it does not happen again. Well done, very well done.
Somewhat ironic - monitoring service will setup better monitoring for monitoring
Anyway, I sympathize investment into Hetzner given how expensive they become.
Thanks @rcy026, really appreciate the kind words ! Though I have to say, I'd much rather earn praise for a cool new feature than for how well I handle things going sideways 😄
You replied to my DM asking about the downtime the same minute I sent it. I think that's kinda something to point out
❤️
BTW, if you like the service (free or paid), feel free to leave a review on https://www.trustpilot.com/review/fivenines.io, it really helps the platform get more visibility.
@emgh and i are creating sixsevens.io to provide monitoring for gay porn websites
good luck competitor
Counting the minutes until it's down again.
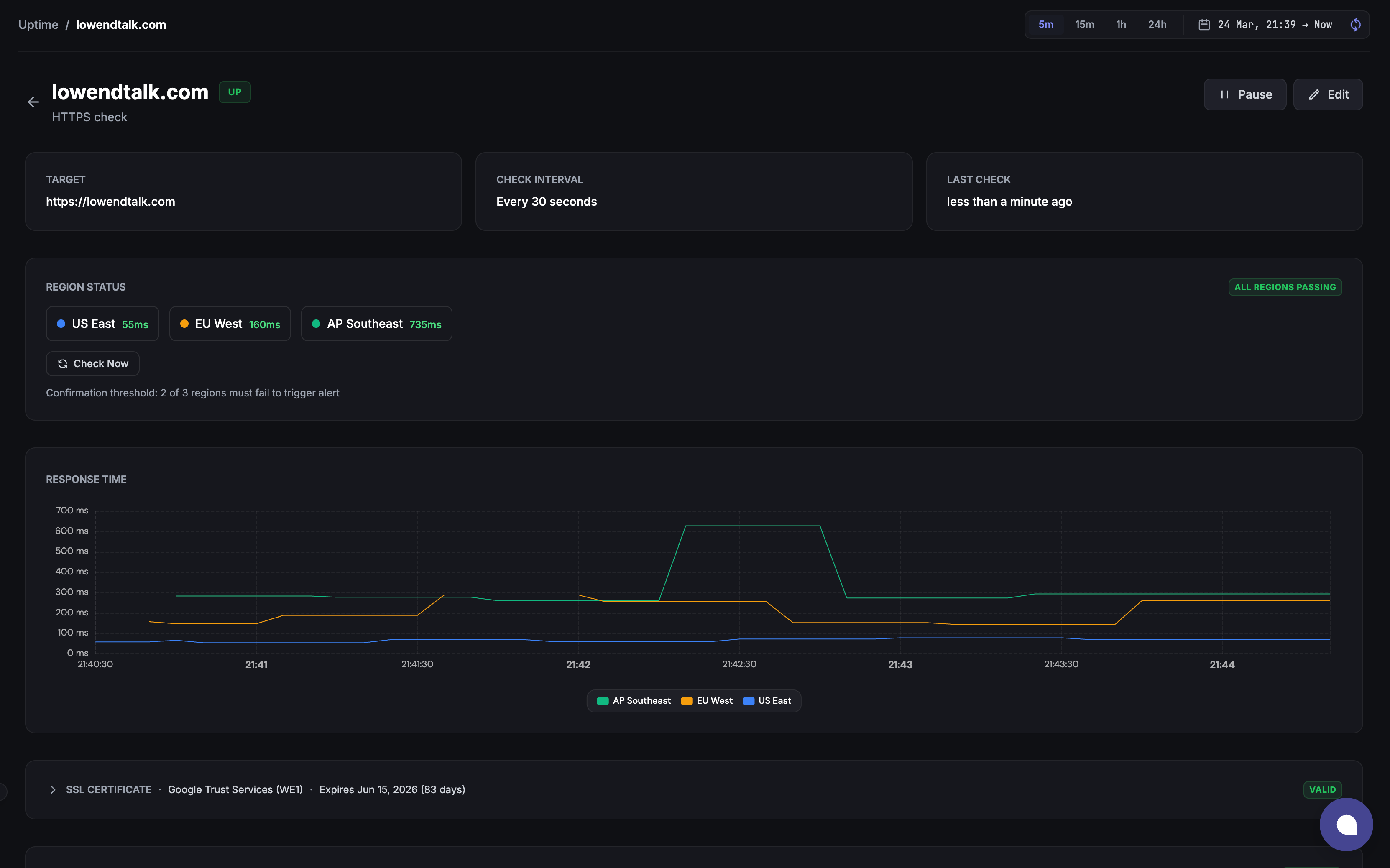
Good news guys, a feature asked since a while just landed to production: HTTPS/ICMP/TCP/DNS monitoring is here, enjoy !")
New update: SELinux enforced mode and Synology support have been added to the agent 🥳