


























New on LowEndTalk? Please Register and read our Community Rules.
All new Registrations are manually reviewed and approved, so a short delay after registration may occur before your account becomes active.
All new Registrations are manually reviewed and approved, so a short delay after registration may occur before your account becomes active.

Comments
LET-50 does not work for plans listed in first message. Even with discount, price is huge. BF is coming, a lot of reputable providers will offer more powerful packages than yours. Bad timing mate, very bad. Your best bet is to launch 1 GB VPS for 9.99EUR/year.
Thank you for feedback.
Unfortunatelly that offer isn't suitable because we pay 1.20 eur pm/IP.
With NAT behind we can easily do that kind of offer.
Best regards, Florin.
Boom..node is offline for at least few hours.
Short-long story.
We bought this server with 128GB DDR4 ECC memory.
After colocating this server, we had 4 freezes in 3 days using proxmox 7.
We reinstalled proxmox with 6th version, but after 12 hours exactly the same effect.
Now we're dealing to debug which is the DIMM which causes this problem, and the huge problem is that we have to pay remote hands for each hardware procedure (removal/install of DIMM).
If anyone can help us with this, we'll be very happy.
Those who are affected by those changes will receive at least one week free service.
Best regards, Florin.
**We know that it comes from RAM because we found on IPMI log "Uncorrectalble ECC" error and it really makes sense because Proxmox is installed on ZFS.
interesting , what brand of ram was this?
I don't rememeber properly, I had this server under 1 hour on my house.
It is for sure Samsung or HP, not anything else.
Best regards, Florin.
So you didn't do a burn in test before sending it off..? Seems like a rookie mistake.
It was 4PM when it arrived and at 6PM it was in datacenter, 1 hour driving.
They did minimal tests and nobody expected tbh to recognize every RAM memory but with some issues after half of a day.
Well it's your server. You should do the testing")
1 hour driving and the server comes back?
No more remote hands fees.
Normally, yeah.
But I have courses all day long.
1 hour after classes and the server comes back?
Put it back to data center a few days later.
Do push-ups to compensate your clients for the downtime.
Well, that's what I did in 2007 when I'm in charge of a university website.
I used a bicycle to move the server to my dorm (100 meters but it's 4th floor without elevator), and paid my helper with a chicken leg.
The website was down for 3 days when I fixed the server.
Every website user who submitted a claim received a small discount on their dorm's electricity bill.
Almost like science fiction episode
ok this is not that common I guess you have bad luck
through out all those years we probably had 3 mem sticks that were corrupt so it is really rare
what you need to do is to run the burn in test you are running but the problem mostly those errors will not be emitted immediately the test has to run few days to see it
other things to check
1- make sure you install the ram in correct slots based on the motherboard instruction
2- re-seat the cpus and while removing the cpu see if any of the pins bent (look closely) (same for ram)
3- change the ram order by replacing stick1 with stick2 and so on (sometimes just by keep changing the order you will find a configuration that will fail on bios POST or the OS boot )
4- check the heat of mem ,cpu and chipset from ipmi while running the tests , it could be the cause not even related to ram and you have faulty fan/s (heating issue)
also it would help if you have screenshot of the full error maybe we can get something from it
The LSI SAS 9305-16i seems to support HW Raid. And ZFS raidz is widely praised.
Way too little info to come to a judgement.
Well known linux problem that can be dealt with (I also experienced it myself)
That may mean a lot or basically nothing. Even the statement itself is doubtful (because it tells what your classmate perceived/thought but not necessarily what really happened).
Yes. It's mentioned frequently here but I'll repeat it anyway: RAID is no backup replacement!
Yes, that is indeed one of the advantages of HW Raid. But there's also a disadvantage: Oftentimes an exact replacement is needed if a HW Raid controller breaks. Not a big problem for e.g. providers with many identical machines or a spare controller, but it can bite normal users with but one single card.
Already running ...
For 4 disks, yes, but not for more.
Careful there, Raid 6 helps to make a rebuild situation considerably less likely, but if an array rebuild were necessary you wouldn't be off better than with Raid 5. They are both snails in terms of rebuilding; in fact Raid 6 is likely to be even (a bit) worse.
A full BIOS post test should detect a RAM error and a good BIOS should even indicate the socket.
@jsg unfortunatelly our BIOS doesn't do so many tasks as on ProLiant Servers.
It boots up in less than 2 minutes, with minimal tests.
The error related to RAM via IPMI didn't said anything about memory socket.
Today our datacenter staff pulled of all RAM DIMMs and connected them again. This was also the 1st step indicated by seller which said that they'll replace any spare part if required.
There could be a connection problem because the server had 2500 km travel from UK to Romania and for sure lot of shocks.
We'll see next hours how it will do.
Best regards, Florin.
Tough luck. Frankly if I were in your shoes I'd stop trying to find a more "elegant" way and just announce some downtime, drive to the DC, rip out 1 mem. bank ("every other stick"), boot and run a memory test (plenty available for Proxmox/debian), then rinse and repeat (put back 1 bank of the bad half and boot and test again) until the bad stick is identified.
It's RAID-1 over two identical 4TB SAS hard drives.
A problem that does not occur with hardware RAID.
The hardware failure was confirmed by university computer lab staff, who is experienced in hardware diagnosis.
I encountered a hard drive failure (single disk no RAID) before this classmate.
I only lost two days, because I have weekly backup.
This classmate knew my story yet he had no backups.
The controller did not fail.
One disk failed, and the manager found a spare that is same model.
We have many servers of the same model.
Sure, but my point was that it's certainly no show stopper.
With all due respect, I don't care what the lab staff said unless I see tangible relevant info. Why? Because if the two drives really failed at the same point in time then with very high likelihood a quite different problem were to be looked at and discussed. As I do not think your classmate was simply lying I have to assume that he - and the lab staff - presumed that both disks failed at the same time but have no hard data to confirm that impression.
Well, then frankly he deserved it.
Yes that's what was to be expected. But still, HW Raid controllers do occasionally fail.
My guess is that one disk failed but he didn't notice, then another failed and machine went offline.
When he requested lab staff assistance, they saw both disks failed.
I can guess as such because he doesn't take care of his server.
I often see 100+ Ubuntu packages pending upgrades on his server.
Moreover, he never installed
smartctlcommand on the server.The server is in a locked room, not the student lab.
If he doesn't go there look for yellow blinking light, and doesn't have
smartctl, he would not know when the first disk failed.Yes, that matches quite well what my take is.
26 hours and server it's still alive.
We're 99% sure about that pulling out & installing again RAM DIMMs solved the problem.
Thank you for those who replied here with tips.
Best regards, Florin.
did you blow on the ram pins before inserting them in before?
I thought you are supposed to dip them in honey and lick?
WARNING!!!
One hour later after I've declared everything is fine, server frozen again.
I've pulled it out from Datacenter and I hope that in about 24h to finish memory testing (let's hope i'll find the problem there).
Otherwise I'll lost my mind because I dont know what's wrong with it.
I'm really sorry for those who have active services hosted on it and also for newer customers which paid but didn't received the service yet.
I promise that i'll keep you up to date.
Best regards, Florin.
the server layout looks interesting what is the model number for this server ?
Good morning!
It is "HPE Cloudline CL3100 G3". I love it because of 12x LFF and 4x SFF (at the same time).
Also it has only PCI-E SFP network cards at 10Gbps.
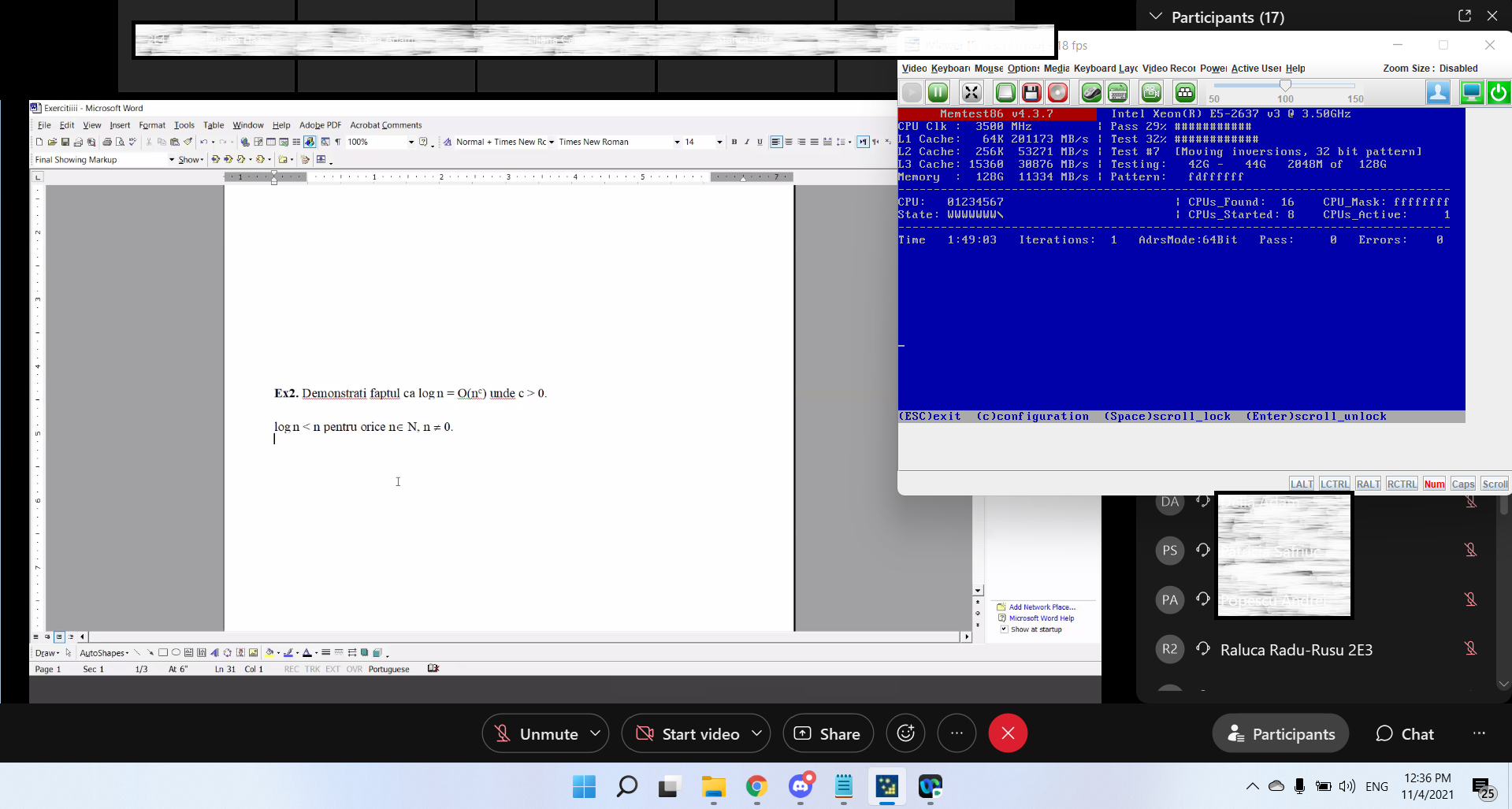
About server's problems: 2/8 Memory DIMMs passed successfully Memtest86 test.
Someone asked few days ago what brand memory is, it is "Micron".
Best regards, Florin.
UPDATE..sad update.
We spent 4x 1h 40' for each test (100% completion on Memtest86 PRO) and it didn't found any issue with DIMMs.
We're very afraid because we have no idea what to do.
Any kind of feedback is welcome.
So, it tests fine at home with the cover off? Have you tried just leaving it running Proxmox to see if it crashes?
If not, but it's crashing when racked surrounded by other servers perhaps as @servarica_hani mentioned it's worth checking the temps?
Thank you for reply!
At home I also covered it because the fans goes crazy during memtest without cover.
Also on IPMI I had a look and there weren't evey anything over 40 degrees.
And about crashing..it taken 26 hours working fine before crash.
Also if I leave it as it is, how this will help me to solve the problem as long I dont know the cause?
Thank you!