


























New on LowEndTalk? Please Register and read our Community Rules.
All new Registrations are manually reviewed and approved, so a short delay after registration may occur before your account becomes active.
All new Registrations are manually reviewed and approved, so a short delay after registration may occur before your account becomes active.
HostHatch Los Angeles storage data corruption (Was: HostHatch Los Angeles storage down)

My storage VPS went down at 7:04 PM PDT (as I write this it's 9:28 PM). It just shows a loading spinner if I try to access it in their control panel:
Opened a ticket and Mike says they're working on it.
I hope it's not involucrated like Chicago (https://lowendtalk.com/discussion/comment/3395311).

Comments
Let's hope not.
I can confirm my Storage LAX is up
mine also offline
I wish they showed the node name in their control panel so we could see if we're on different nodes.
Same for me. Just came here to see if it was affecting anyone else too.
I was on the Chicago server that involucrated and I made this LA server my primary, with backups to Chicago and London.
Should I post the rest of my server in case anyone wants to move away from them since apparently I'm bad luck?
Not sure why there needs to be a thread, but sure")
We're working on it.
mine is up too
seems no any email notifications
Sadly mine's down too, I dont usually check my storage server since its kinda "cold" storage for the backup of files. I only do check it when I upload new stuff for archival.
Hearing this in public first rather than the provider through email or other means is a bit concerning.
Came back online at 9:49 PM but then went down again at 9:55 PM (PDT)
Because you don't often send email notifications while outages are happening, the control panel doesn't display announcements about outages, I wanted to see if it affected other people (since sometimes outages were isolated to just my VPS), and I was worried it'd be another big event like Chicago.
It's not uncommon to have users create threads during outages, although it seems like it was more common on WHT compared to here
Why shouldn't there be a thread? This is the second time you seem to be down with issues. These threads are helpful for people like me and this would have been an issue for me if I was a customer. I will hold back from purchasing storage until things seem more safe on your side of things.
Mine's back but needs a manual fsck
but I'm about to go to sleep so I'll deal with it tomorrow morning. Hopefully it's not broken to the point that fsck won't fix it.
You're supposed to think that but not say it")
Just to be clear, one node was down, which is about 5% of our storage users there, and not all storage in Los Angeles.
this happend to mine too, about 1-2months ago
It's a fairly common thing to see forced fsck's after a hard reboot on large disk machines.
How does one fix the same? I am noob on this so will gladly appreciate some help.
Centos7 --> FDE setup. Have entered the LUKS password and it has spit out some weird errors. Not sure how to proceed. thanks
Dear diary,
Fsck!
What's the error?
If it's a damaged LUKS header, you'd better kiss that data goodbye since you're not getting any of that back if you don't have a good copy of the header.
verified from livecd and found many checksum errors. For those who could mount the corrupted storage, do not forget to verify the contents.
I love you guys, but those 5% of users should really have been notified. I think adding node name into the panel + sending outage emails would go a long way.
It’s not unless there is some hardware issue, or some layer of the storage setup is defeating fsync etc. With a block device that holds data and fsyncs correctly, it is always just a matter of replaying journal on hard reboot. A modern filesystem will never be corrupted in this scenario
https://lowendtalk.com/discussion/comment/3397397#Comment_3397397
Is it this issue again?
status.hosthatch.com doesn't even show having had an outage. Is that no longer a valid way to find out for myself whether things are having a problem?
I ran
fsck.ext4and there was a bunch of corruption which is a bit concerning. I've got around 4000 inodes in lost+found now, across both the root volume group and data volume groupSo far I've noticed that both the Syncthing and Netdata executables are corrupted, as are several of the cached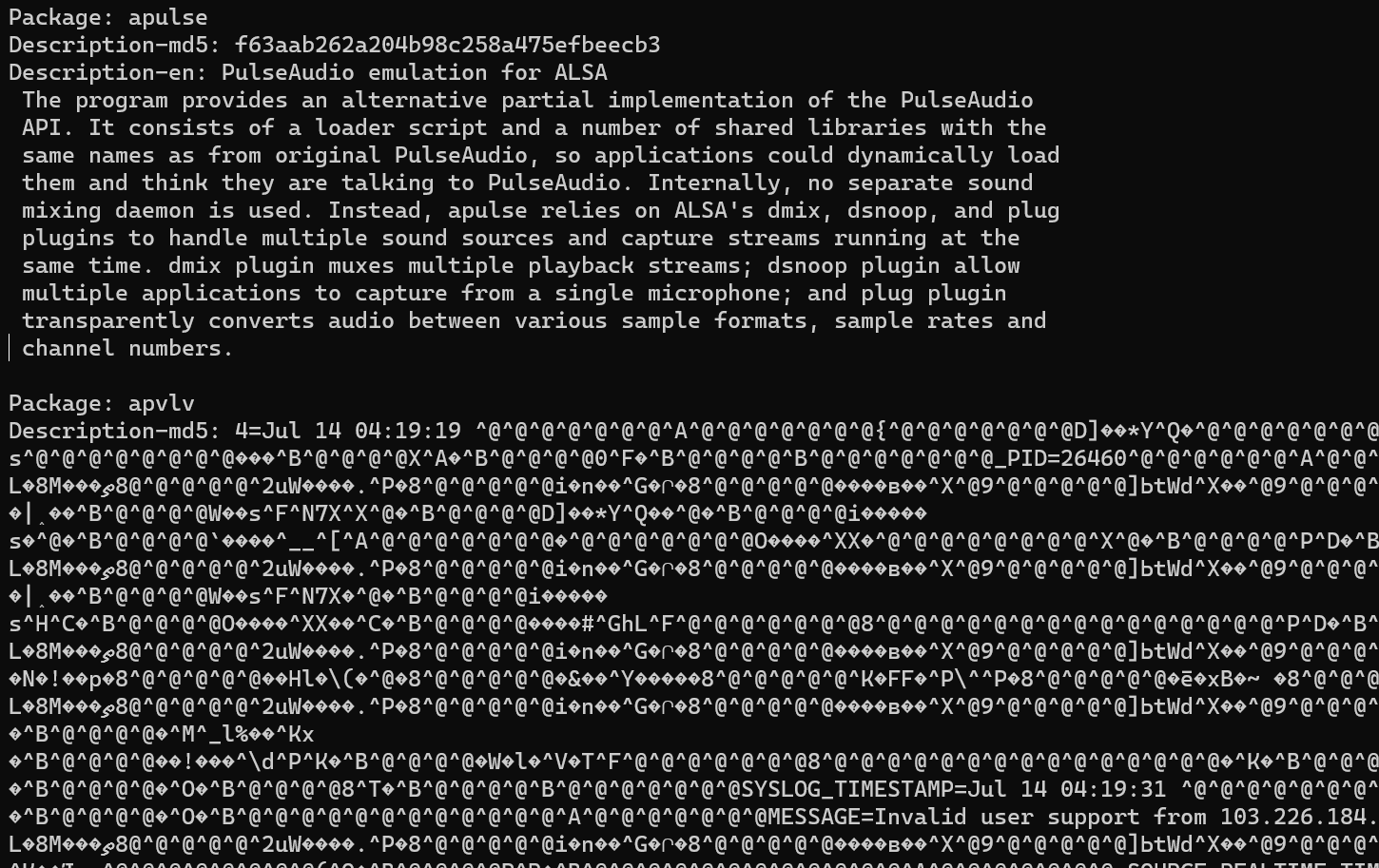
aptpackage lists.apt updatefailed to run because several of the lists had a chunk of the systemd journal in them 🤔I'm working out if I can verify the files based on my Borgbackup backups (
borg check?), otherwise I'll just restore everything from backup.Sad too hear yet another data loss story from hosthatch... whats that 3-4 in the last 2 years... (that iv heard about)
Most of the important data seems fine, which is good. The system booted fine so all the core files required to boot are there. I'm probably still going to restore everything (~5TB) from backup.
Since op seemed to have recovered from the issue, I don't want to get deeper but I think knowing there was an outage was beneficial for me.
Looks like another case of corruption of data at rest... very weird failure mode. Maybe understandable if that systemd log data was recent, but "Jul 14"?
For borg the best bet is probably to mount the latest backup and use another tool to compare. I don't think it has any option to force checksum
Working on it... there's some data corruption.
Since the backup is encrypted, it'd have to download and decrypt all the data to compare it. At that point I may as well just restore the entire backup anyways. I realised that I actually only have ~1TB in the backup as most of the space used on the server is actually backups from other systems where I can just use
borg checkto check it.It looks like might be a way,
borg create --files-cache disabled, not sure if that will give useful log output alone, if not followed withborg diff