



























All new Registrations are manually reviewed and approved, so a short delay after registration may occur before your account becomes active.
[Technical Showcase] Decoupling Metadata & Streams: A Serverless Media Architecture via Cloudflare
 serverlesscore
Member
serverlesscore
Member
Hi LET Community,
I’m a long-time lurker and finally decided to join this amazing community. As a developer obsessed with high-concurrency and "Doing More with Less," I’ve spent the last few months building a media orchestration layer that redefines how we think about media servers.
Today, I’m excited to share the technical architecture behind my project. While I do have a commercial version in the works, I want to keep this thread strictly focused on the technical implementation and how I leveraged the Cloudflare ecosystem to solve traditional storage bottlenecks.
The Architecture Diagram
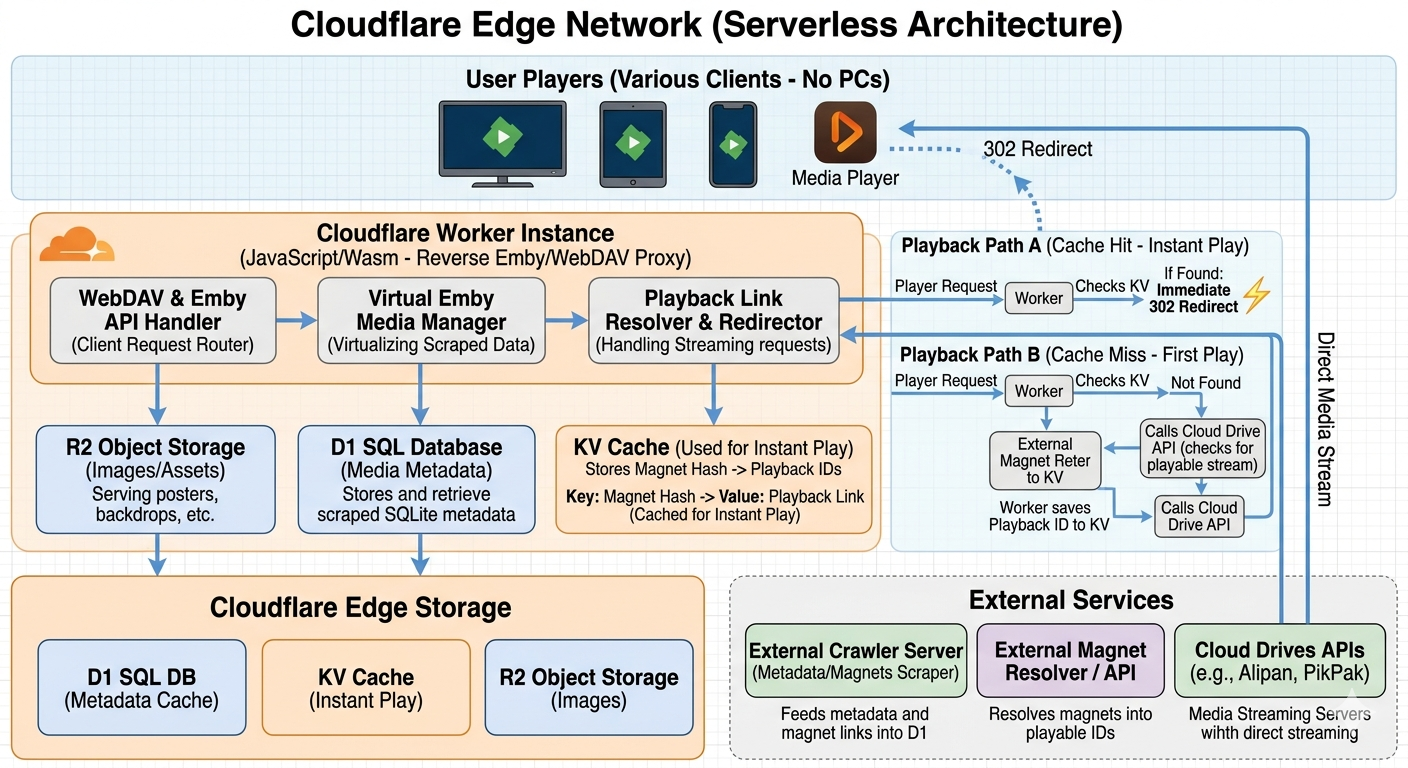
The Problem: The "Heavy" Media Server
Traditional setups (Emby/Plex) are storage-heavy and CPU-intensive. They require large disk arrays and decent hardware to manage metadata and streaming. For a "Low-End" enthusiast, this is often the biggest barrier.
My Solution: Zero-Storage, Pure-Routing Architecture
My goal was to build a system that owns no data but routes everything. I’ve decoupled the Control Plane (Metadata) from the Data Plane (Streaming Assets).
1. The Virtual WebDAV & Emby Proxy (Edge Logic)
Running entirely on Cloudflare Workers, I’ve implemented a stateless virtual file system.
- Protocol Reverse Engineering: I reverse-engineered the Emby API so the Worker can "impersonate" a standard Emby server.
- Metadata Mapping: Instead of mounting a physical drive, the Worker dynamically constructs a Virtual WebDAV layer by querying scraped metadata from a D1 SQL Database.
- On-the-fly Construction: When a client requests a file list, the Worker generates the directory structure in real-time. No local I/O, no disk consumption.
2. Decoupled Storage Layer
- D1 & R2: I use Cloudflare D1 for structured metadata and R2 for assets like posters and backdrops. This ensures the "Poster Wall" lights up instantly regardless of the library size.
- KV Cache (The Instant-Play Secret): I use KV to store the mapping of
Magnet Hash -> Playback Link. This reduces the latency of resolving magnets to a few milliseconds.
3. The 302 Redirect Magic (Traffic Passthrough)
This is the core of the "Pure-Routing" philosophy. The Worker never touches the actual video bytes:
- Request Interception: When a user hits "Play," the Worker resolves the magnet link via an external API and retrieves a direct stream link from cloud drives (e.g., Alipan, PikPak).
- Edge Redirection: The Worker issues a 302 Redirect, pushing the heavy lifting (bandwidth/streaming) directly to the cloud drive's CDN.
- Result: TBs of traffic bypass my server entirely. The "Server" is just a lightweight traffic controller.
Conclusion
By combining Serverless Workers with a Distributed Metadata Layer, I’ve created a media server that requires zero disk space and minimal compute on the host side, yet scales infinitely.
I’m currently refining the commercial implementation, but I’d love to hear your thoughts on this architecture. Does anyone else here experiment with virtualizing media libraries via Edge Computing?
Looking forward to a great discussion!

Comments
TL;DR: He is excited.
Okay, how can I calculate the cost of this serverless solution vs using vps + cloudflare reverse proxy
That's a great question. The cost-efficiency of this architecture is actually its biggest selling point compared to the traditional VPS + Reverse Proxy setup. Here’s the breakdown:
1. Zero Bandwidth Cost (The 302 Magic)
In a traditional VPS + Reverse Proxy setup, all video traffic (TBs of data) must flow through your VPS. You’d need a high-bandwidth port and pay heavily for data egress.
In my architecture, the CF Worker only handles the "Control Plane" (HTTP headers and logic). Since the video stream is 302-redirected directly to the user's player from the cloud drive (PikPak/Alipan/RD), the bandwidth cost to you is ZERO.
2. Extreme Concurrency on Free Tiers
A single Free Tier CF Worker (100k requests/day) can theoretically support thousands of concurrent users.
3. Minimal Starting Cost (Pay-as-you-grow)
Summary:
While a VPS has a fixed monthly "rent" regardless of traffic, this Serverless solution costs almost $0 in infrastructure until you hit massive scale. Even then, your only real expense is the back-end storage accounts.
That's the problem. You will be juggling with multiple accounts
looks to be AI post
According their profile, they just created this account and they work for Cloudflare.
https://lowendtalk.com/profile/serverlesscore
Guilty as charged. I use AI to summarize and streamline my posts, and the entire core—from the WebDAV logic to the Emby reverse engineering—is pure Vibe Coding. I don't work for Cloudflare; I just build on their edge because it's the most efficient way to handle 16k+ titles with zero disk. Stay tuned for the commercial drop.
That's not juggling; it's a pluggable, distributed architecture. Scalability is about routing, not manual work. That's what makes a robust system.
How do you store the content? If not store, where do you get it and how do you index it with plex/emby/jellyfin?
We only store magnet links in Cloudflare D1. I built a WebDAV server using Hono and wrapped it in a custom Emby 'shell' to handle the UI/indexing. Zero media storage on our end
Magnets, metadata, and posters are all fetched via crawlers. Everything is automated
How this can be utilized for dmca content?
Guess that explains why i had a small seizure reading this. Geez, the level of lazyness is just amazing. Build some crazy system, be oh so excited, lack the time to work out a decent write up. If that says anything about the quality of the system/code i'd rather pass...
Since the videos are stored on third-party cloud drives and our Workers/servers host zero video files, it is naturally DMCA-resistant. Plus, the serverless architecture makes it immune to most attacks
Fair point. I spend my energy on Vibe Coding the architecture rather than polishing the prose. I'd rather the system's performance speak for itself. I'm working to get a live demo online later today
I see.
Sounds like that's against the terms of the Cloud drive storage providers.
But you're seriously looking for input into your commercial piracy solution? Ask the AI if that's a good idea.
I've been using DVR with satellite for over 25 years. I don't know how the fuck people put up with anything less than "instant" playback controls. I'd rather spend hundreds on stored local content than deal with lag or buffering. Fuck that noise.
To clarify, this is a commercial demo showcasing the ability to instantly populate Infuse poster walls and stream 16k+ titles fluently. The roadmap is to evolve this into a SaaS: users connect their own storage (RD, PikPak, etc.), and my system provides the curated magnet indexing. No more manual searching—just pick your interests, offline to your own drive, and play instantly in Infuse.From a technical and legal standpoint, the SaaS backend only stores magnet metadata. Since users stream content through their private cloud accounts, it avoids the typical DMCA risks associated with centralized hosting.
So it scales for you, not the end users? They have to pay you and the cloud provider?
So you're selling an indexer which functionality already exists, you're just trying to make it more user friendly?
Doesn't this functionality already exist for free and all they need to do is pay for the cloud drive?
https://github.com/debridmediamanager/debrid-media-manager plus Stremio?
Instead of vibe coding, you should have been searching for existing solutions and including in your OP why anyone would want to use your service instead of existing ones.
Good questions. My goal is to abstract the complexity away for different user tiers. I'm offering two paths:
The main difference compared to projects like plex_debrid is the "Turnkey" experience. Tools like plex_debrid still require users to find their own RSS/magnets, manage indexers, and handle local database syncing. My solution comes with 16k+ pre-indexed titles and instant metadata syncing—no manual configuration required. It’s for users who value their time over "DIY" setup.
Since you are familiar with this space, what’s your take on this two-tier approach? I'd appreciate your input on how to make this architecture even more competitive.
I'm not familiar with it, I use arrs with torrent and nzbs and local storage.
But now you're saying your own storage, so that doesn't fit the scaling you initially talked about.
16k sounds low. This just movies alone? If it ain't for TV, movies and porn, who are you targeting that they wouldn't just use an IPTV service?
You’ve got a sharp eye—you nailed it. The 16k library is indeed heavily focused on JAV content, which is the core niche I'm targeting.
To keep the demo compliant and showcase the architecture's versatility, I’ve also indexed the Top 250 highest-rated movies.
The reason people would choose this over IPTV or a standard "Arr" setup is the UX vs. Maintenance trade-off. IPTV is great for live TV, but for VOD, it often lacks the high-end metadata experience of Infuse. My goal isn't to replace the massive "Arr" hoarders, but to provide a "Zero-Configuration" boutique service for those who want instant, high-quality playback on Apple TV without the headache of managing local storage or complex indexers.
It’s all about providing that "it just works" vibe for specific, high-demand niches. You are welcome to give it a try first; the development is mostly complete. I’ll be dropping the official commercial offer thread once I finish the final polishing.
Check it out at: ivibe.fans
I didnt understand the concept. Can somebody explain in a simpler way?
TL;DR he wants to serve lots of video files without the legal risk that actually comes with storing by chaining together a lot of "serverless" tools together that makes many drives on different providers seem like one unified device so that he can watch his autofetched gooning content (JAV) more efficiently. Presumably, this is either a business or he's got an insatiable appetite for the stuff. There's a lot of AI slop I didn't read but that's the gist of it
bro pause the llm for one second damn
I don't think he can. Its screwed so deep into his brain by now that any attempt to form a human sentence will just come out as "Gdfk hnbl sderf".
we've all been there
Well, kind of? I am not sure if LLM counts as a substance.
i think it does
seriously it does give a rush
Actually some kind of dopamine release due to the feeling of having archived something probably really isn't far fetched and being able to trigger it at the push of a button could lead to repetitive behavior. Who knows maybe a couple years down the road we will see some kind of LLM Anonymous groups?