


























All new Registrations are manually reviewed and approved, so a short delay after registration may occur before your account becomes active.
On the future of hardware pricing

Disclaimer: Analysis only, not financial advice. Sources: Micron whitepapers, NVIDIA GTC 2026 keynote, Futurum Group, SemiAnalysis InferenceX, Jensen Huang's 1GW iso-power slide. All projections are inference from cited data.
Hardware prices are being distorted by AI demand, and it won't resolve until at least 2027. Here's why — and what it means for hosts and powerusers.
The prisoner's dilemma
Hyperscaler capex/revenue sits at 10:1 to 15:1. $500B committed in 2026 alone against ~$50B industry revenue [1], with an additional $500B+ committed through 2027 [2] [3]. Nobody stops building because stopping means losing market share. Sunk cost does the rest.
How inference actually works
GPU inference runs in two phases with fundamentally different computational profiles:
- Prefill — all input tokens processed simultaneously. Massively parallel matrix multiplication. High GPU utilization. This is what GPUs were built for.
- Decode — output tokens generated one at a time, sequentially. Each token depends on the previous one — parallelization is architecturally impossible. GPU sits mostly idle between steps, waiting on memory reads.
Four solutions have been deployed to attack this:
- Batching — sharing GPU compute across concurrent users, amortizing idle decode time
- HBM capacity scaling — keeping the KV cache (the running memory of the conversation) close to compute, reducing fetch latency
- SOCAMM LPDRAM [4] — CPU-attached memory tier up to 2TB per CPU, staging warm KV cache outside expensive HBM
- LPU (Groq) [5] — dedicated decode hardware with 500MB on-chip SRAM per chip, statically compiled execution graph, zero scheduling overhead. Does one thing: generates tokens fast.
The result is a structural collapse in cost per million tokens — not software optimization, hardware architecture:
| System | Year | Tokens/sec/GW | Cost/Mtoken | vs H100 |
|---|---|---|---|---|
| H100 NVL8 | 2022 | ~2M | $4.40 | 1x |
| H200 NVL8 | 2024 | ~2.8M | ~$3.00 | ~1.4x |
| GB300 NVL72 | 2026 | ~70M | $0.13 | ~35x |
| Vera Rubin NVL72 | H2 2026 | ~700M | ~$0.013* | ~350x |
| VR NVL72 + Groq LPX | H2 2026 | ~24.5B | ~$0.00037* | ~12,250x |
| Feynman/Kyber (VRU) | 2028 | TBD | TBD | ~50,000x+** |

*Approximated: VR = 1/10th GB300 per NVIDIA [6]. VR+Groq = 35x more tokens/watt vs Blackwell at ~2x combined rack cost [5].
At iso-power (1GW): 600K Hopper GPUs produce 2M tokens/sec. 300K Vera Rubin GPUs produce 700M tokens/sec using half the hardware [5]. The floor has not been reached.
**Feynman confirmed for 2028 with new GPU, Rosa CPU, LP40 LPU, and Kyber NVL1152 (8x density of Rubin NVL144) [7]. Performance trajectory is author's projection from generational improvement pattern, not NVIDIA's stated figure.
For hosting operators: you've seen this before
The traditional hosting industry prices on core count and memory density. Core pricing is being dramatically challenged. There is no better analog than this:
| CPU generation | Year | Cores (2S) | Revenue/RU vs baseline |
|---|---|---|---|
| Ivy Bridge-EP | 2012 | 20 | 1x |
| Haswell-EP | 2014 | 36 | ~1.8x |
| EPYC Naples | 2017 | 64 | ~3.2x |
| EPYC Rome | 2019 | 128 | ~6.4x |
| EPYC Genoa | 2022 | 192 | ~9.6x |
| EPYC Turin | 2024 | 256 | ~12.8x |
Same rack unit. Same colocation rent. The 2012 server still worked in 2019 — it was just priced out of existence by a neighbor in the same rack doing 6x the work at the same footprint cost. GPU token economics follow the same curve, compressed into 24 months instead of 12 years.
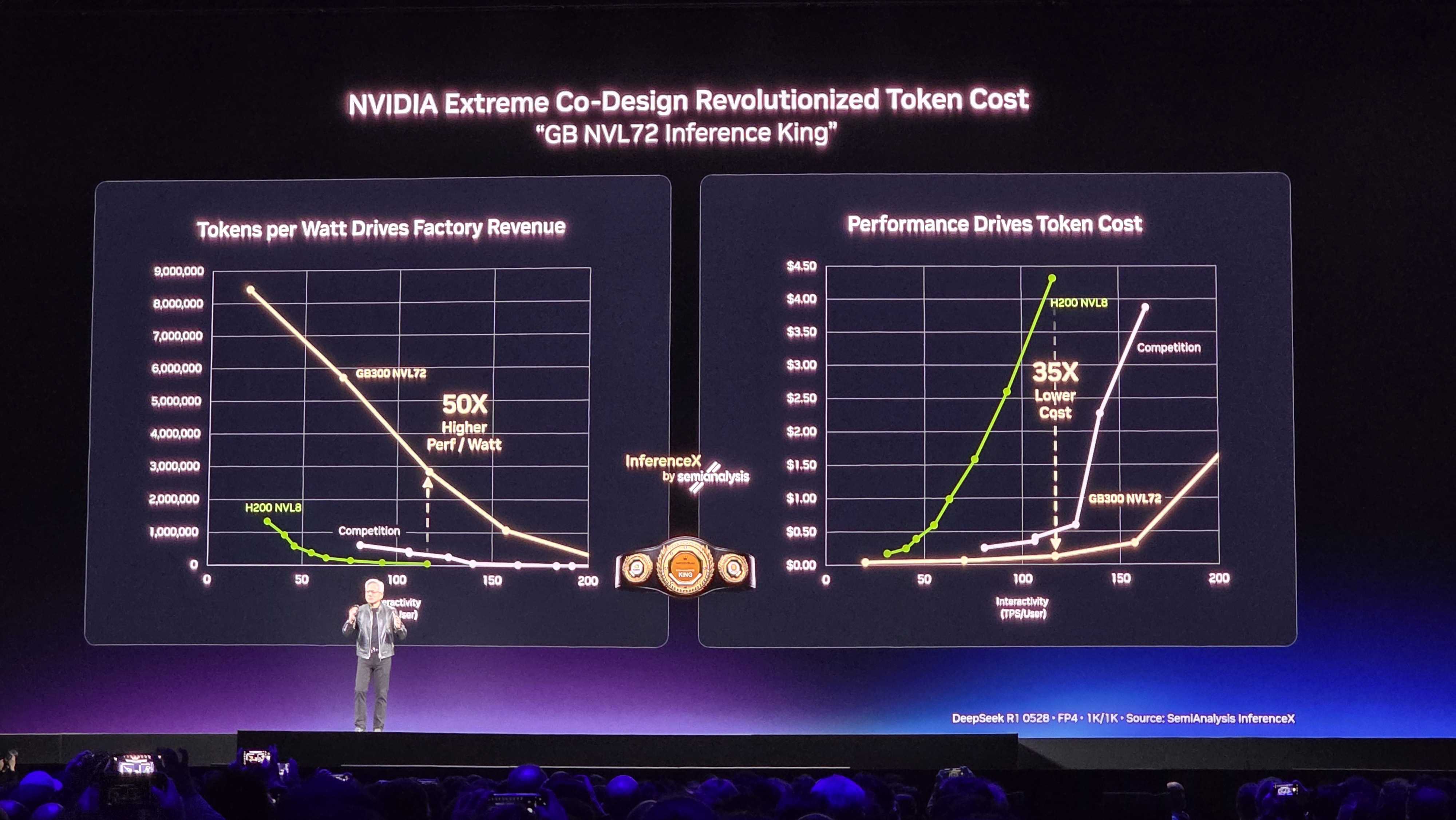
The idle capacity problem
$500B in 2026 AI-directed capex [1] at ~20% inference allocation implies approximately 2 trillion tokens/sec of new inference capacity — derived from Jensen's own 1GW iso-power comparison: 300K Vera Rubin GPUs at 700M tokens/sec per GW [5], blended across the Blackwell-dominant 2026 install base.
Current industry demand is approximately 127M tokens/sec — derived from ~$40B in 2026 AI revenue [8] divided by a blended ~$10/Mtoken average across consumer and enterprise tiers ($10/Mtoken × 127M tok/s × 3.15×10⁷ s/yr ≈ $40B). The gap is roughly 15,000x oversupply before Vera Rubin ships.
Even under aggressive Jevons Paradox assumptions — cheaper tokens drive proportionally more usage — demand growing 100x still leaves 150x excess capacity. The token price floor is arithmetic, not speculation:
Price floor ≈ electricity cost ÷ tokens per kWh
At VR+Groq efficiency and $0.05/kWh, the floor approaches ~$0.00037/Mtoken (consistent with table above). Current GB300 pricing of $0.13/Mtoken is already ~350x above that floor.
What this means for hardware pricing at Q4 2027 / Q1 2028
Market rationalization here means a specific trigger: hyperscalers stop or significantly reduce new orders, either from token supply glut making additional capacity economically indefensible, or from liquidity pressure as medium-term corporate bond markets tighten against sustained negative ROI. Hyperscalers raised $121B in new debt in 2025 alone [9], with Morgan Stanley and JP Morgan projecting $1.5T in total debt issuance required over the next few years [10]. Oracle already faces a financing gap from FY2027, with Barclays warning it could run out of cash by November 2026 at current trajectory [11]. CDS spreads — the bond market's forward-looking default insurance — have been rising across the sector [12].
This aligns roughly with the end of NVIDIA's currently committed production pipeline. If either condition materializes earlier — and the oversupply math suggests it could — the price corrections described below arrive ahead of this timeline, potentially as early as mid-2027.
Compute (GPU)
The 2026 installed Blackwell base faces a competitive token economics gap of 350x against Vera Rubin alone, 12,250x against VR+Groq.
Hourly GPU rental rates on H100/H200 class hardware will reprice downward as operators compete for utilization against a market where newer hardware produces orders of magnitude more output at the same power cost. The stranded asset isn't theoretical — it's hardware being delivered today against a depreciation schedule that assumed 5 years of competitive relevance.RAM (DDR5)
Prices will be lower than the February 2026 peak. The 400% ramflation was driven by AI factory demand absorbing total DRAM production capacity.
As HBM4 and SOCAMM displace DDR5 for the highest-demand AI workloads, and new fab capacity from Micron's Hiroshima expansion comes online in 2027, the DDR5 market should see meaningful relief. The exact magnitude depends on whether consumer and enterprise non-AI demand recovers the slack, or whether the market overshoots into a glut. Directionally: lower, timeline and depth uncertain.NVMe
SOCAMM LPDRAM handling warm KV cache in-flight reduces the NVMe use case to cold KV archival only — sessions idle for hours or days.
This is a significant demand reduction for the high-performance NVMe tier. The workload that justified $50-80/TB NVMe pricing — fast random-access KV staging — is being absorbed by the SOCAMM tier on-board. What remains for NVMe is large-block sequential cold storage, a workload that does not require NVMe's random-access performance premium. Expect pricing pressure on datacenter NVMe as the AI workload profile shifts.HDD
Inconclusive near-term, but NVIDIA has drawn the boundary for us.
The Vera Rubin POD architecture defines four explicit memory tiers [13]:
| Tier | Hardware | NVIDIA product | Latency |
|---|---|---|---|
| Hot KV | HBM4 on Rubin GPU | ✅ | Nanoseconds |
| Warm KV | SOCAMM 2TB on Vera CPU | ✅ | Microseconds |
| Warm-cold KV | STX rack NVMe via BlueField-4 | ✅ | Milliseconds |
| Cold archive | — | ❌ | Seconds+ |
NVIDIA's BlueField-4 STX rack extends GPU memory into NVMe for active KV reuse — sessions resuming within hours. It is not designed for day-scale or month-scale retention. The cold archive tier is explicitly outside the POD boundary, and NVIDIA has no product there.
At Vera Rubin's 700M tokens/sec throughput, even a 1% session persistence rate generates petabytes of cold KV and artifact data per day per POD. The I/O profile — large sequential writes, infrequent full-block reads, latency tolerance in seconds — is exactly where HDD is cost-optimal versus NVMe.
S3-compatible object storage on CMR nearline HDD, positioned as the cold archive tier that the NVIDIA POD architecture intentionally leaves unaddressed.
The hardware still works. It's just being priced out of existence — on a 24-month cycle instead of a 12-year one.
Question for longtime hosts: Do you still have 2012-2014 CPU models in production?

Comments
I would like to thank you @host_c, @ReliableSiteHosting, @ServerBachelor, @tentor, @forest and many other users for direct or indirect help.
Initially, I want to make capex + opex breakdown. But, GTC happened. Ironically, the best repudiation for building up AI inference capacity came from Jensen Huang's slides.
No clue what I did, but I appreciate the shoutout and admire your work nonetheless.
You're welcome. Honestly, I don't remember the exact details. But I remembered you. It has something to do with hardware/pricing discussion. I guess I should mention @Levi, @layer7, @fiberstate who participate on this topic too
That is true, the price increases we started to see now (in early 2026) were mostly caused by the provider's necessity of expansion with the new hardware at increased market price. One can hope the AI datacenters either quickly transition to their optimized dedicated solutions or close down altogether once the craze is over. Similar to what happened after the crypto mining craze a couple years back - the price of hardware should get significantly cheaper then once the demand falls. Just my opinion.
Otherwise we just have to survive this period somehow, possibly not this many $7/y deals but I'm sure we will make it")
Thank you AI lords
I am afraid no tokens were generated to write the post
Hyperscaler won't go down unless their traditional money-making business went down. But those GPU players may face serious write-off. There's no details whether this new class of components are backward compatible.
I hope hosts are watching the market news closely, because the future of $7/yr deals is at stake!
On the AI-slop consumer side. It's going to be great. Claude, Kimi, etc is running "limited" double, triple promotion. This must be terrific for @PulsedMedia
I hope the prices drop back to normal soon.
I hope I can buy gum for a nickel, again.
Flagged
it never will. it's gonna be a new normal. the only thing that will never change is lowend spirit.
Hard to tell. Look at what happened with Gasoline. Once it starts to increase, it never goes back to the original price.
I see a lot of people wanting 1G of RAM and more, declining offers with less RAM, unwilling to cut corners themselves and optimising software and it's configuration to be able to fit in what was previously named "lowend spirit" (not OGF).
Counter flogged
AI doesn't have same problem as it scales linearly with RAM and its bandwidth not gpu speed. That's why RAM is getting expensive. Hopefully processes upgrades (like recent Qwen 3.5 which is very smart and small) will lower the demand for RAM. However that won't make OpenAI contract for 40% RAM go away magically.
I believe there's lag between spot pricing and the price end-user paid. And prices could go back to normal pricing once supply returned.
We actually decided to stock up on hardware in advance for this exact reason.
Most signals we’ve been seeing point toward prices continuing to rise, especially on the memory side. It honestly feels like RAM pricing has been creeping up almost every week lately.
Looking back at pricing around late 2025 already feels kind of surreal now - hard to imagine we’ll see those levels again anytime soon.
Curious if others here are taking a similar approach or just waiting it out?
Never fully
AI does not scale linearly. For example, doubling the context size, the ram usage quadruples.
That's why efficient model has an edge, through sparse attention and compression
don't forget this hot news today, may change the price and uncover other "player"
https://www.investing.com/news/stock-market-news/dell-technologies-stock-rises-as-rival-super-micro-tumbles-93CH-4572757
https://www.bloomberg.com/news/articles/2026-03-17/memory-chip-crunch-to-persist-till-2030-sk-chairman-says
https://www.cnbc.com/2026/03/20/nvidia-gtc-2026-agentic-ai-chips-tech-download.html
The company is hiking prices for its T-Head AI computing chips by between 5% and 34%, it said in a statement. It’s also raising the cost of its Cloud Parallel File Storage service by 30%, it added. Alibaba shares rose as much as 4.2% in Hong Kong on Wednesday
https://www.bloomberg.com/news/articles/2026-03-18/alibaba-hikes-ai-computing-prices-up-to-34-after-demand-soars
Alibaba Group Holding Ltd. is raising prices for its AI computing and storage products by as much as 34%, joining a host of big tech firms moving to capitalize on surging demand in the hope of recouping hefty investments.
The company is hiking prices for its T-Head AI computing chips by between 5% and 34%, it said in a statement. It’s also raising the cost of its Cloud Parallel File Storage service by 30%, it added. Alibaba shares rose as much as 4.2% in Hong Kong on Wednesday.
The new pricing, which includes Alibaba’s Zhenwu 810E chip, comes after the company launched a major structural revamp this month to focus on monetizing AI. China’s e-commerce leader introduced a series of products, including an agentic AI service for businesses called Wukong, that it hopes will tap into national enthusiasm for the technology.
Tech giants from Alphabet Inc.’s Google to Tencent Holdings Ltd. are trying to monetize AI-related services, responding in part to growing concerns that massive AI investments aren’t generating adequate returns.
Tencent has taken initial steps to monetize the shift toward agentic AI. Last week, the company announced a more than fourfold price hike for its Hunyuan foundation models on its agent developer platform. Baidu is planning to raise the price of its AI cloud products by as much as 30% from next month, a spokesperson said on Wednesday. Google also recently announced a plan to raise prices.
AI chips are one facet of a broader campaign by Alibaba, which is due to report earnings on Thursday, to become a leader in the technology. The company has been among the most aggressive investors in and advocates for AI since DeepSeek fired up the local tech industry. Chief Executive Officer Eddie Wu has pledged more than $53 billion toward infrastructure and AI development — an outlay he’s said the company could surpass over time.
Alibaba leads Chinese large language model makers in open-source but has so far struggled to translate that into a significant commercial lead. Just this month, Alibaba lost a star model developer, raising questions about the company’s broader approach to AI. The company this week unveiled a big corporate restructuring, creating a new Token Hub business unit to encompass its entire AI portfolio and refocus on profiting from the technology.
Alibaba is making those moves at a time Tencent is gaining momentum in AI, particularly in the field of agentic AI services that claim to carry out a series of complex tasks for users. Tencent in just the past week introduced several signature products aimed at tapping a national enthusiasm for AI agents like OpenClaw — automated services that perform real-world tasks. They underscore an initial advantage for the WeChat operator: it’s grouped China’s entire universe of apps onto a single platform with 1.4 billion users. The company is now working to integrate its own AI agent into WeChat, automating tasks like hailing a ride or booking restaurants, according to a person familiar with the matter.
https://www.bloomberg.com/news/articles/2026-03-19/alibaba-ai-business-is-free-call-option-first-eagle-fund-says
OpenAI, Anthropic Deals Power Abu Dhabi’s $100 Billion AI Bet
https://www.bloomberg.com/news/articles/2026-02-17/openai-anthropic-deals-power-abu-dhabi-s-100-billion-ai-betMGX was conceived in 2023, shortly after the launch of OpenAI’s ChatGPT sparked a global scramble for dominance in artificial intelligence. Abu Dhabi decided it needed a dedicated investment vehicle, creating a fund that now ranks among the world’s most consequential backers of the technology.
When Anthropic unveiled participants for its latest funding round this month, the firm joined as a co-lead investor. That followed a run of high-profile bets from MGX, which is racing toward a target of more than $100 billion in assets under management, backed by Abu Dhabi’s sovereign wealth and its deep ties to Wall Street.
To get there, it plans to spend as much as $10 billion annually on select companies over the next few years, its AI investment chief Ali Osman said in an interview.
Those figures are staggering for a standalone fund, even by the standards of Abu Dhabi’s constellation of investors that have poured tens of billions of dollars into finance, technology and infrastructure in recent years. Osman acknowledges the pace is striking, but his rationale is simple: He expects generative AI to grow into a $700 billion market over five years, a forecast larger than many mainstream predictions.
“Management teams are still having a hard time projecting out what the total size of the prize is,” he said.
Amid that broader uncertainty, MGX is powering ahead. Alongside Anthropic, the firm has taken stakes in OpenAI and xAI in an unusual investing hat trick that’s given it exposure to three of the most closely followed firms ahead of potential public listings. It joined BlackRock Inc. on a $40 billion takeover of Aligned Data Centers last year, teamed up with Silver Lake Management on a deal for a chipmaker, and has helped assemble a consortium seeking to raise $30 billion to fund AI infrastructure.
MGX's Big Bets
Source: Bloomberg reporting
The breadth of those wagers reflects a view that the industry will require unprecedented levels of capital. That money could evaporate if an AI bubble bursts
, but Osman is bullish. “I mean, $30 billion is a big number, yet it’s a tiny number,” he said. “Whether you’re a bull or a bear in AI land, we’re talking trillions.”
Those ambitions have made MGX a critical cog in the United Arab Emirates’ mission to become an inexorable political force in AI. The fund, conceived on a paper napkin three years ago, is at the center of a pivot in Abu Dhabi: After the city’s sovereign investors spent years plowing cash into the financial sector, the focus has shifted in recent years to advanced technology.
Read More: Mideast Money Drives Silicon Valley and Wall Street’s AI Ambitions
Abu Dhabi’s moves come as the race among Middle Eastern nations for AI dominance intensifies. Saudi Arabia’s Humain said Wednesday it invested $3 billion in xAI, while Qatar’s wealth fund has also made a series of high-profile bets in recent months.
The spending spree is also an echo of a decade ago, when Middle Eastern oil wealth poured into SoftBank Group Corp.’s $100 billion Vision Fund that backed many infamous startup busts.
The stakes are higher now. A huge portion of the stock market is tied to promises of tremendous economic gains from AI, which aren’t here yet. Silicon Valley’s giants keep pledging greater sums on computing resources, spurring a cottage industry of data center development that’s built on huge piles of debt.
Abu Dhabi’s Deepening Push Into Artificial Intelligence
Sovereign wealth funds’ investments in AI, data centers and chips, sized by deal amount, through the end of October 2025
Note: A selection of subsidiaries and entities over which the funds exercise control are included in each fund’s deals.
Source: Analysis of news stories published by Bloomberg News, official announcements and regulatory filings
But MGX executives insist they are not spending carelessly. The firm is structured in a “very risk-managed way,” diversifying deals across geographies and asset classes, said David Scott, the firm’s chief strategy and safety officer. “We’re not in places where there’s a lot of speculation.”
Until now, the fund has offered little detail about how it picks targets or how much it expects to spend. Scott and Osman spoke with Bloomberg at the World Economic Forum, in Davos, Switzerland, for the firm’s first in-depth interview. They described their approach as unique, drawing in regular requests from global funds seeking to partner on deals.
“We’re just able to unlock exquisite opportunities that most people can’t access,” Scott said.
Much of that access flows from its chairman, Sheikh Tahnoon bin Zayed Al Nahyan, the influential Abu Dhabi royal whose reach cuts across technology, finance and politics. He oversees vast swathes of Abu Dhabi’s oil wealth as chairman of its biggest wealth fund, its top lender and the city’s largest-listed conglomerate.
Read More: Gulf Royal’s $1.5 Trillion Empire Draws Bankers and Billionaires
During a trip to Washington, DC last year, the royal met US President Donald Trump and helped tee up a pledge to spend $1.4 trillion in the US, a commitment that is said to have aided the UAE’s pitch to buy advanced American chips. Months earlier, MGX had agreed to bankroll Trump’s Stargate plan; the fund is also an investor in the new US TikTok entity, and holds a $2 billion stake in Binance bought using a stablecoin tied to the president’s family.
Donald Trump and Sheikh Tahnoon bin Zayed Al Nahyan at the White House in March 2025.Source: Abu Dhabi Media Office
MGX draws further institutional heft from its links to Mubadala Investment Co., which co-created the AI investing firm alongside Sheikh Tahnoon’s G42. The wealth fund is run by Khaldoon Al Mubarak, a prominent executive in Abu Dhabi and a central figure in the country’s global investment strategy.
When MGX was unveiled in March 2024, the ambition was clear. “We are entering a new era where Abu Dhabi is not only a global technology leader, but also shaping the AI roadmap of the world,” declared Peng Xiao, G42’s CEO and a board member at MGX.
MGX is one of many investing powerhouses in Abu Dhabi, which together oversee assets worth $2 trillion. Many of these have existed for decades, though officials have recently set up newer firms focused on specific sectors and priorities, including L’imad Holding Co., chaired by the crown prince.
That’s part of an effort across the oil-rich Middle East, where wealth funds are shifting from simply allocating assets to investing in strategic areas for their own economies.
Of these, Abu Dhabi hosts the “most sophisticated” investor, according to Winston Ma, adjunct professor at NYU Law School and former head of North America for Chinese sovereign wealth fund CIC. “MGX is the frontier,” he said. “They can make bold investments into cutting-edge technologies that may have long-term impact.”
Executives from both Mubadala and G42 joined the board of MGX, and Ahmed Yahia Al Idrissi, the CEO of Mubadala’s direct investments platform, was tapped to run it.
“We’re a new fund, old team,” said Osman. “So, we’re known quantities.” He himself worked for Mubadala when MGX was set up, having spent around 15 years leading teams investing in tech and life sciences.
“There is no other way to keep up,” Osman said, explaining the rationale for setting up MGX.
MGX’s AI investment chief Ali Osman, left, and David Scott, the firm’s chief strategy and safety officer.Source: MGX
There are elements that set MGX apart in Abu Dhabi. For one, it’s looking to tap global investors, a rarity in a city that’s typically seen as an exporter of capital. And unlike many others, MGX is designed like a venture or buyout firm, where partners receive carried interest and external investors are eager for returns.
That setup allows for the right “due diligence and risk taking,” according to Scott. He said, though, that the closest comparable entity isn’t in private equity or venture but Nvidia Corp., the chip titan that invests frequently in AI software and cloud computing startups.
A former American diplomat and National Security Agency agent, Scott joined in early 2025 after serving in the energy sector and the Abu Dhabi government.
Abu Dhabi Funds’ Interest in AI Has Swelled in Recent Years
Ranking of the top industries involving investments from the emirate’s three sovereign wealth funds based on the estimated annual number of deals, through the end of October 2025
Note: Only the top 10 industries with the highest number of deals across 2020–2025 are shown. Deals with multiple or unknown industries are not included. No investments in fintech and crypto were captured in the dataset for 2020.
Source: Analysis of news stories published by Bloomberg News, official announcements and regulatory filings
Since inception, MGX has hired from private equity and venture firms. About a third of its headcount, roughly 30 people, is based in New York.
It has built a portfolio of about 20 firms, according to Osman, including Databricks, a San Francisco-based company that lets businesses deploy AI capabilities. Since MGX first invested in it in 2024, Databricks has doubled its valuation to $134 billion, becoming one of the largest tech startups.
But MGX has steered clear of categories popular with other investors. The firm says it hasn’t backed any of the apps built on top of generative AI models, finding the business too volatile, and it hasn’t touched robotics, quantum computing or energy providers. Despite going big on data centers, MGX has avoided neo-clouds — companies that rent out computing capacity.
Osman mentioned two theoretical projects to explain why MGX has avoided these deals. He imagined one as “a data center in the middle of nowhere, built by an unknown developer,” while another is built in an area zoned for the industry, by a developer with a long track record, with a 15-year contract involving a large cloud-computing provider.
“Not all compute is created equal,” he said. “When we say ‘bubble,’ yes, there will be capital loss. But that’s because things just don’t look the same.”
‘Not-Obvious’ Bets
MGX executives also see themselves as contrarian.
“We are in the business of not-obvious,” said Osman. As evidence, he cited MGX’s stake in Anthropic. It first came in as a shareholder when the firm was valued at $17 billion, according to Osman. Anthropic has since become a breakout success — its revenue run rate has increased to $14 billion, and its most recent funding round was at a $380 billion post-money valuation.
Still, many of its investments look fairly predictable for a fund with a lot of cash focused on AI. Databricks had already received funding from Nvidia and Fidelity before MGX joined. Rather than backing one horse in the AI race, like SoftBank has with OpenAI and many VC firms do, MGX invested in three.
It’s effectively an index fund strategy, betting that at least one will emerge as a winner. The firm is primarily looking for startups willing to take large checks to support huge computing bills and keep up in the heated competition for talent. An entrepreneur was told MGX would only invest $500 million or more.
“AI isn’t just a VC play anymore,” said Jane Smith, the chief AI officer in EMEA for ThoughtSpot, a software firm. “It’s long-term infrastructure, similar to energy, transport and telecoms.”
Osman denied MGX has an investment threshold, and dismissed the idea that its investments in AI model developers are in direct commercial competition.
He sees OpenAI as holding an edge in the consumer market, Anthropic with enterprises and xAI on robotics. “They compete for talent. They compete for capital,” he said. “We think that the [total addressable market] is so significant that the next net dollar gained is not at the expense of someone else. The market size is so huge.”
Overall, MGX has an advantage over competing investors because it looks at the “entire stack” of AI development, Scott said.
By investing in a chip manufacturer, Altera, MGX has insight into the capabilities of upcoming chips. Through its data centers, it can see the kind of capacity that’s being built over the coming years. And with its AI investments, it can measure the upcoming demand.
“We can kind of see where the puck is going,” said Scott.
— With assistance from Priyanjana Bengani and Demetrios Pogkas
((Updates to add Humain's xAI investment in paragraph nine.))
https://www.bloomberg.com/news/articles/2026-03-18/podcast-ai-is-being-built-to-replace-you-not-help-you
</While headlines, industry hype and employers suggest a near-term revolution that will make workers more efficient and successful, Acemoglu offers a more measured—and unsettling—view.
He agrees that recent advances, particularly in “agentic” AI, are moving faster than expected, but that today’s systems fall short when it comes to reliability, reasoning and real-world understanding. That means any sweeping, immediate transformation of jobs and productivity remains unlikely in the near-term. But the uncertainty about what comes next is higher than ever, and Acemoglu warns that tech giants are overwhelmingly focused on replacing workers rather than complementing them. This, Acemoglu says, risks both weaker productivity gains and serious social consequences.
He argues that the greatest economic benefits would come from “pro-worker AI” that enhances human capabilities, enabling workers to perform more complex and valuable tasks. But current business incentives, market structures and policy frameworks favor labor replacement. Without a shift in direction, he cautions, large-scale job displacement—particularly among white-collar workers—could strain labor markets, depress wages and destabilize democratic institutions.
Acemoglu also emphasizes that shaping AI’s trajectory requires both public debate and policy intervention. He criticizes the current “AI race” narrative, particularly between the US and China, as misguided and potentially harmful, advocating instead for a broader focus on practical applications such as healthcare and manufacturing.
You are correct algorithm-wise, I'd also say that AI is at the brink of current compute capabilities so you need to use high-speed RDMA and that is where the actual problem comes from with expansion.
127B+ models especially with bigger contexts will need a lot of RAM or HBM/GDDR and those are simply not available on one mobo/card yet, was it a non-RAM bound process, you would start hitting things like CPU->PCIe exhaustion (like in case of NVMes), IPC lags, CPU stalls/bottleneck.
BUT, what I meant is that it's pretty linear in terms of resource consumption - more ram and bandwidth = more performance at the same speed (not the intrinsics of the algorithm or context, because context is quadratic as you mentioned and algorithm depends on GPU ram speed and GPU->GRAM interconnects but those are usually beefier than CPU->RAM).
You can't just throw ram and ram bandwidth at your typical site/SAAS and expect linear growth in productivity/capabilities.
This AI craze is reminiscent of the Bitcoin/Ethereum/Solana mining craze because expanding there, until the process was also pretty clean - power converted into tokens almost directly, this one though bites our sector and many other rather than just gaming/GPUs.
As a note, I'm not sure what you're referring to. So, I had AI to rephrase your reply.
So, you think AI scales linearly as you throw more resources. It's because the inference workload is embarrassingly parallel (That's what AI said as it extrapolate the following statement). There's no non-linearity outside of the inference pipeline. The model weights are read-only, KV cache is fully isolated per request. So, threads does not need to coordinate. Unlike SaaS sharing mutable state, which compounds to certain bottleneck.
As for the AI craze, I think we should separate the two forces: the demand and the supply. Adoption of AI could be identified over its ability to improve or replace human-bounded output. As for the supply, there's the technological ability × providers offering AI services + the underlying infrastructure. The hyperscaler, forgot the linearity of the demand side and assumed they could make profit out of the technology with specified stats and amount of unit.
It’s time for people to write efficient code like we used to.
Thanks for reaching out to the hardware support department, your efficient code has been rewritten with the use of electron and perl.
Jeez, the ai slop kills me with corpojargon")
We see quite moderate demand for AI despite being one of the few offerings in Budapest with AI capable CPUs (power limits in DC do not allow much GPU hosting). So the mass demand is probably hyperscalers. General population and thus our target audiences are not aware or are wary of the AI (despite honestly it being the easiest thing to setup, compared to some cryptotoken based chatroom VPS or even prod wordpress VPS).
On the ram front every week I am seeing higher prices for ddr4. It is absolutely brutal.
It's going to take time for people to get accustomed to and ordered one to self-host. Meanwhile, hyperscaler have very aggressive outlook which is impossible to achieve. They probably will idle large chunk of installed capacity .
It's not going to go down until hyperscaler stopped doing supply squeeze
HA HA HA
So, long story short, we gave away some servers for free to some customers that are in a bad spot today and they are non-profit organizations, consider it as a sponsorship,yet as backup servers they can live with 32 bg ddr4 all day long, so since we don't use modules of that small size, we need to get some, so we asked 3 of our suppliers for a quote on 2x 16 Gb DDR4 ECC Registered even if 2133 MHz, and we got back ±100 USD / 16 GB DDR4 module...... at that point I replayed to them, " at that price point, stick it up your ass ".
Now, don't get me wrong, I am not a cheap-skin, yet, paying 100 USD on 16 GB DDR4 in 2026 - fuck no.
So yes, welcome to 2026 reality. It is a fuqing mess.