



























All new Registrations are manually reviewed and approved, so a short delay after registration may occur before your account becomes active.
CPU steal times with various providers

Most of us have various servers with different providers, and I decided to write a bit different review. I usually monitor my servers with many monitors, and one is self-hosted Zabbix. It can tell you many details and here we are mostly talking about CPU steal. Here is a short description for those who are not familiar with this term:
CPU Steal = The percentage of time spent in involuntary wait by the virtual CPU while the hypervisor is servicing another virtual processor.
Now that's one indicator to see if the hosting provider is overselling their host nodes. This is the reason why I thought people would be interested in these stats. You can see CPU steal from your server with 'top'.
These stats are from last 7 days and all these virtual servers are low-end packages that have a single vcore and around 1 gb ram. Some of my servers are running actual services that are done with PHP so servers are basic LEMP environments. These services are pretty similar so no big differences there and some servers even have solid CPU steal when idling. Pink color is CPU steal in these graphs
Netcup VPS G7 (average 12.07%)
BuyVM LU (average 7.99%)
Cloudcone LA (average 14.34%)
Scaleway Start1 (average 5.62%)
Virmach ATL (idle, average 3.22%)
Towwwer.host (idle, average 9.25%)
Now even I highlighted some providers here with CPU steal, it can vary depending on the host node. For example, I have two very similar VPS with BuyVM LU and one doesn't have any steal. Some providers like Cloudcone or Scaleway are having great amount of steal even when you are moved to a different host node.
There are also providers that are not having any CPU steal even when I thought so Hostsolutions.ro, Alphavps, OVHcloud....
During the years I have already killed some VPSs with quite bad results, and the worse was almost 50%.
One thing that I noticed that almost none of these highlighted servers don't have IOwait which can be also one indicator of overselling. I have a couple of servers with high IOwaits and similar LEMP usage than servers above. Maybe I will do a different review of those ones later.
Feel free to share more experiences with your CPU steal times

Comments
For NetCup, G7 is 2 generations old, and a VPS with them does not have guaranteed CPU. The RS line has unlimited CPU usage and a guarantee of steal being below 3%, and the 2000 G9 is one of the best options right now, considering CPU performance per dollar.
BuyVM does have unlimited CPU on most plans, so (ab)use is practically guaranteed. CloudCone, Scaleway and VirMach seem to be well-known for their poor CPU performance (somebody provided a screenshot of steal of over 50% on Scaleway too).
I know that G7 is not the latest but RS line is almost same price every month that some of these servers are yearly.
Also Php-friends and Avoro are solid options when looking for dedicated CPUs
Yup, it goes something like this (assuming well balanced host nodes)
CPU: Avoro ~ NetCup > PHP-Friends > Hetzner AX
RAM: PHP-Friends > NetCup > Hetzner > Avoro
Disk: NetCup > Hetzner > PHP-Friends > Avoro.
Generous and decent bandwidth on all systems.
On average, the best system is NetCup, then Hetzner or PHP-Friends, and Avoro at the end.
I know @Francisco wont be stealing CPU’s in the future. LU is getting Ryzened up.
About Ryzen, we haven’t had a case of stolen cpu for quite sometime as well")
CPU steal doesn't always mean oversold hypervisors, but can also be the hypervisor throttling the VM due to too high average (e.g. try use your burst allocation on lightsail and see 85-90% steal).
With that said - nice metrics")
I'll add a few just because:
mvps.net:

e2enetworks:

first-root:

heficed (this one had an issue which caused a bunch of downtime):

DigitalFyre:

Ginernet:

flowvps:

Skylonhost:

Providers with absolutely zero iowait (or less than 1% basically):
Doesn't hetzner ax line is pretty much the best bang for the buck.
i mean for 40 eur you got ryzen dedicated server with 15k passmark.
Depends on the workload. Single threaded? Yup, the 3600 is your best bet. But multi threaded tasks, like most server workloads? The 15.6 euro Root Server has an average GB5 of 3142, while the AX41-NVMe (7194 GB5 average) starts at 34 euro, with ECC an additional 5 euro, and a 39 euro setup fee. Bottom line is, the RS has a roughly 1.18x GB5 per dollar.
Not quite, we cap people that rim their shared cores non stop.
The E3's are harder to manage for. We put out the shared plans with good intentions (basically a cheap way for people to get a taste) but since we don't do automatic capping it can get a bit busy.
The Ryzen's provide a mountain of buffer for us with most nodes running around 40% utilization. Some new stallion updates cuts down node side system interrupts a lot as well")
Francisco
Yeah, I assumed it was because it was an older node and you prefer showing leniency. I'm sure your Ryzen nodes are lovely, if a bit hard to come by.
They aren't in LU yet") I'm loading the pallet today.
I'm loading the pallet today.
I was supposed to ship it like 3 weeks ago but we kept siphoning off nodes to feed LV & NY. But, we put on hold any new nodes for those locations until LU gets shipped")
Slabs are also going out on this shipment! Couldn't be more excited for that. We've been promising them in LU for at least a year at this point.
Francisco
If you don't mind me asking, what app are you using to get these handsome charts?
Stats are gathered using netdata (does per second metrics) - then Prometheus scrapes the endpoints every 10 seconds. Data is then visualized in Grafana.
Awesome, I already use Netdata, might have to research on how to get prometheus and grafana!
Any guides you followed? will be appreciated!
Thanks
Nice always love seeing stats like this. Here's on 2 of my upcloud servers with Centmin Mod's native cminfo sar-cpu output
7 day average for cpu steal is 0.02%, max is 0.43% and 95% percentile is 0.09% and 99% percentile is 0.20%
7 day average for cpu steal is 0.00%, max is 0.01% and 95% percentile is 0.00% and 99% percentile is 0.00%
If anyone ever reports a high CPU steal, we investigate the matter and always at the very least offer free migration. We have automation in that there are maximum thresholds for CPU usage before a node is locked off. We constantly improve this and have recently added more specific scenarios for accuracy. Right now, we have 7 nodes out of hundreds that are sub-optimal in terms of CPU usage where some abnormal bursts of CPU steal may occur, but they are all already locked off and they're not anywhere close to being "overloaded." Actually, right after typing that I decided to spin up an SSD256 on our highest CPU usage server.
First, I'll provide the CPU usage & load levels.
For reference, the second-worst server is 5% lower CPU usage than this. Definitely not optimal, but again, this is our worst server. We miscalculated the quantity of OpenVZ VMs that got moved here because we didn't correctly anticipate who would be using it at what time since we were also moving dozens of other servers, and there was also a glitch with SolusVM (recently patched) that caused high idle CPU usage per VM running certain operating systems (and this server ended up with a lot of those.)
Now for steal time/other, arbitrarily grabbing it every few seconds --
Bonus -- bench.sh
Bonus -- Steal percentage/other as partial Geekbench runs
Bonus -- Geekbench5 but with 1GB RAM (due to error with 256MB.)
https://browser.geekbench.com/v5/cpu/4707640
Then again, if you feel like there's a problem, go ahead and check it out and if you see high steal time or other objective issues, create a ticket with your findings and there's usually no reason for us not to move you to another node. If the server's actually higher than we'd like it to be, we sometimes reach out and request some people to move voluntarily, it's a win-win situation.
@VirMach My apologies, I mixed you in with CloudCone and Scaleway by mistake. Your performance isn't necessarily poor, but rather restricted. You have your limits quite explicitly defined in your FUP/AUP, which is certainly different from the norm. Certainly haven't heard bad things about you overall, just that your CPU policy is quite unusual.
Our intention with being clear wasn't to be strict or restrictive, but rather set a line so we cannot arbitrarily take action underneath that. This is to try to avoid going by a policy that says "whatever we deem to be abuse" because then customers have no idea what that could end up being.
We always try to be lenient where possible.
Outside of some rare edge cases, this generally means for CPU, as long as it's available and you are not bursting to maximum usage for multiple hours, you should be fine. We have almost entirely switched to an automated system which is much more lenient and gives ample time and explanation in every situation for the customer to decide to either lower their usage (and a lot of times with assistance, it ends up being that they had unknown malware or software acting up) or to upgrade their service.
We've gotten very good at balancing out nodes and being lenient where it matters and generally keeping everyone happy.
Perhaps we'll consider changing our AUP to be more in line with what we actually do since we're much more lenient. It would just make it more difficult to take action when required and we wouldn't want to invoke the "whatever we deem abuse" rule as much as other providers do since it's vague.
Well initially when I set up Prometheus first time, I followed a guide to get the config right, but Netdata has documentation for a prometheus setup as well, after all Netdata simply exposes a prometheus friendly scrape endpoint.
Graphs are graphs, and you configure them as you see fit in Grafana - I guess we all have our different ways of doing the same thing.
Cause ECC RAM and CPU steal have...what in common exactly?
Nothing. Because that specific discussion was about CPU performance per dollar, and it was (IMO, validly) assumed that ECC was a requirement. So, we need to add that cost to the base price for a valid comparison. I genuinely worry about the attention span of the average LET reader, sometimes.
What is considered a high CPU steal? Unfortunately, I had two hostnames in new-relic with same hostname, so I don't have long term stats, but watching it for the last hour its been between 3-10 with bursts to 15 on SEAKVM14. CPU load average reports 0.05, 0.17, 0.12. On SEAKVM5, I haven't seen the steal above 0.5 for the same watched period.
Also, for BF specials, I don't think people feel free to ticket asking for less congested servers, they'll just take it and bitch about it being overloaded (and half expect that to be the case, anyway). I paid $6.99 for 1 CPU and keep that in mind for expectations.
FYI, I don't think a GB5 score of 334 is anything to boast about. I've got several Virmach's with GB5 scores in the 300's, whereas every other server I have except one (3TB storage server, 6% average steal) has scores 500-636, all Low end. The Virmach CPU used is E5-2660 v2 @ 2.20GHz and on another VPS provider with a lower generation CPU E5-2660 @ 2.20GHz, it has a GB5 scores of 554 and 565. So my general impression is less CPU/dollar with Virmach vs other providers, especially with a 4 core server having a GB5 multi of 1062 and a 2 core GB5 multi from another provider is 1070.
Edit: last time I updated my spreadsheet, I had two servers with E5-2660 v2 @ 2.20GHz and now both have Intel Xeon E312xx (Sandy Bridge), so that sucks for me. One hopes to get better CPU's each change, not worse ones.
p.s. billing.virmach.com (despite 14ms ping from me), is hella slow (25 seconds to load pages) in responding atm.
It's relative but CPU steal is of concern if it impacts how much of your VPS/guest server's cpu it can use or if it's consistent over time (which is why I measure not just it's average but min, max and percentile metrics for daily and weekly averages from above cminfo sar-cpu output). For example when 0% cpu idle reported (cpu is use) and you see cpu steal or you see cpu steal and you aren't able to use 100% of your cpu.
anyone able to do a test for contabo SSD vps. They have a great bang for buck.
Depends on your use case, but I consider anything above 10% to be very high.
I have three VPSes with BuyVM: One "Slice 4096" (which has "dedicated CPU usage") in Las Vegas, and two "Slice 512" (which has "fair share" CPU usage) in Luxembourg and New York. All three have relatively low CPU steal percentages compared to other providers. You'd think that the Slice 4096 would have lower CPU steal, but in reality the small New York one has consistently lower CPU steal, at least up until the past day.
(green is Luxembourg, red is Las Vegas, blue is New York)
I spoke to Francisco about it and he said there's some known issues with some config thing that may be causing issues with CPU steal, so I'll check it again in a few weeks.
Some providers I use have very good CPU steal percentages, even though they don't have dedicated CPU. My @VirMach is almost always below 1.0%:
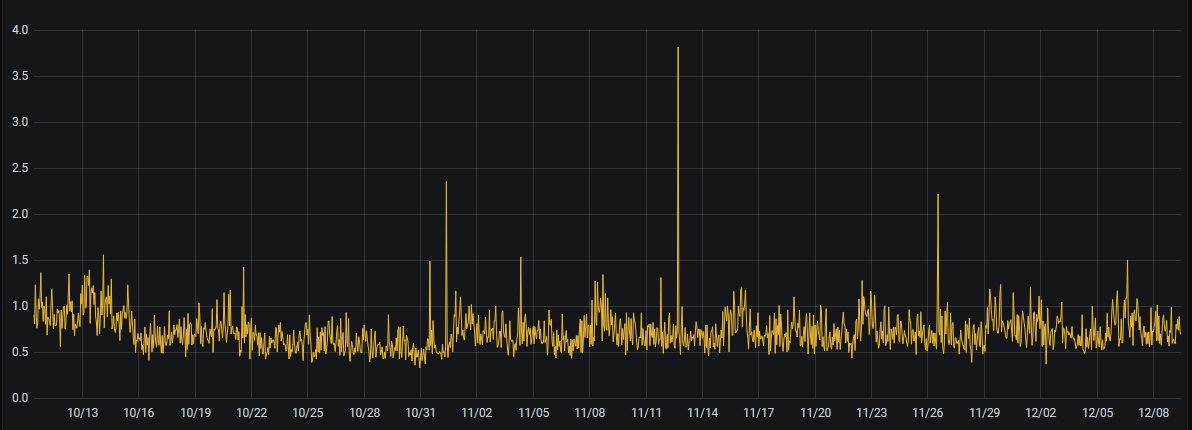
And CPU steal on two of my other VPSes (@QuantumCore, and a BudgetNode @Ishaq storage VPS) is so small that it barely registers on a graph. Usually less than 0.1%.
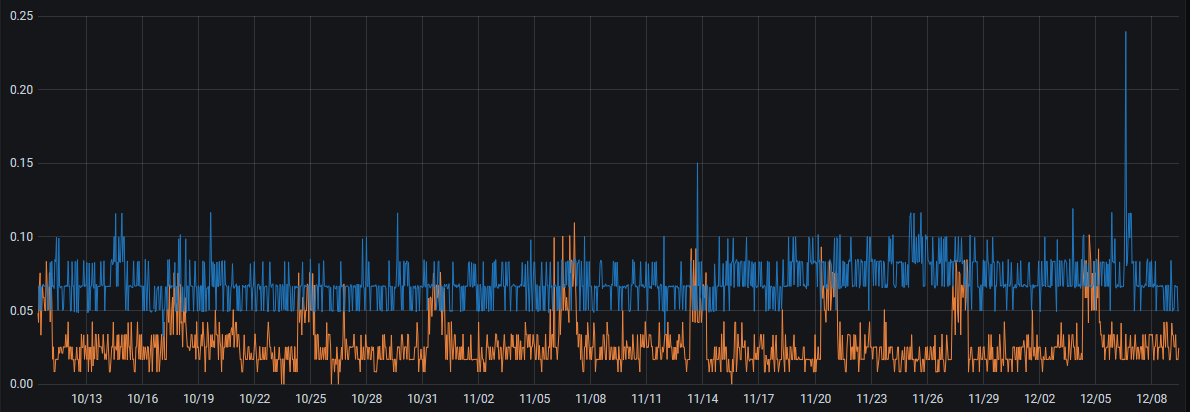
Note that some providers patch their kernel to not report stolen CPU time... In those cases you usually just see
0.0%all the time. I've seen BinaryLane do that.