



























New on LowEndTalk? Please Register and read our Community Rules.
All new Registrations are manually reviewed and approved, so a short delay after registration may occur before your account becomes active.
All new Registrations are manually reviewed and approved, so a short delay after registration may occur before your account becomes active.
Racknerd Strasbourg France - Global Packet Loss
 stephen_hill
Member
stephen_hill
Member
in Providers
Hello
First time posting here.
I have a Racknerd VPS which I got in the Black Friday sale. I haven't really set it up yet, it has a couple of unconfigured services such as nginx and mysql. The VPS is just idling - doing nothing.
Today I noticed my SSH connection kept hanging/freezing.
I reached out to support who ask me to check my server's ping with https://ping.pe/
I did this and there is intermittent packet loss globally.
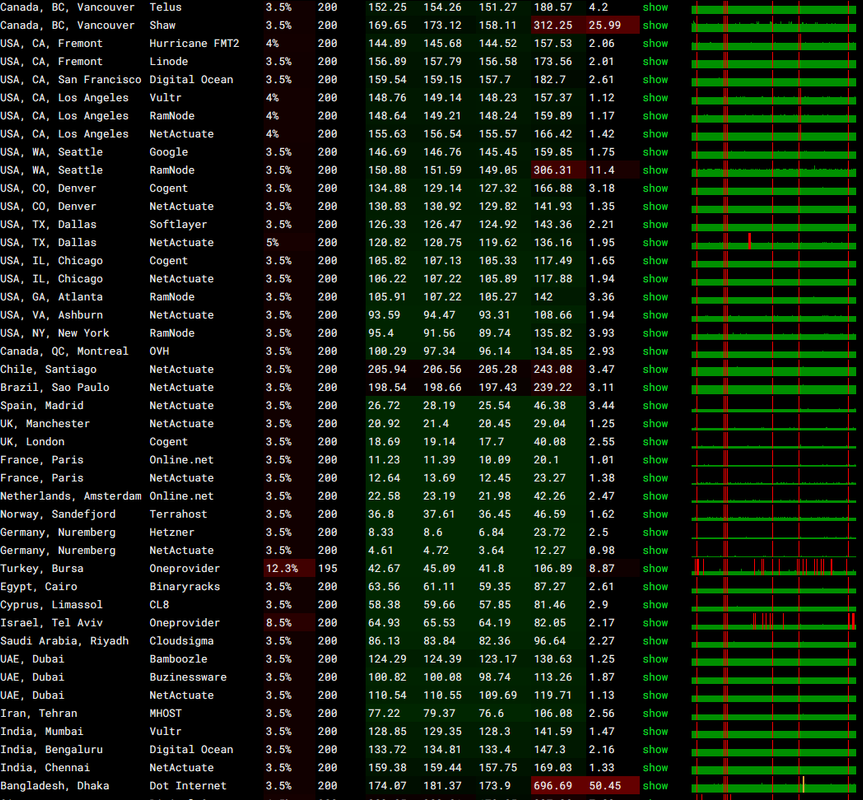
I kept trying to have a discussion with their support, but they keep telling me nothing is wrong. Their responses have basically been:
- Looks fine to me
- It could be your internet connection
- Wipe the server and start again
So I'm just wondering if anyone else is experiencing problems with Racknerd's France datacenter (AS29066 VELIANET-AS).
Also, is this lack of support normal for Racknerd?
Many Thanks
Stephen

Comments
Show mtr of one of this ping.pe Locations.
Ping doesnt tell us where The issue is
Thanks
To be fair, 3.5% packet loss on ICMP traffic is pretty low. The ones that spiked higher could possibly be attributed to issues with those specific check points. Anything that runs that many tests from that many locations at once, you try to assume that a few of them could experience a temporary issue at the same time just as a healthy measure.
See if you can boot the server into a recovery ISO of some kind (dealer's choice) with networking and then run the test again. If you've done that and had the same result, tell their support that you ruled out an OS issue and how you did so, put the ball back in their court. But make sure to add at least one MTR that show where the packet loss begins. If you can show the packet loss on TCP traffic, even better.
Hi HostSlick
Here is a couple from Europe.
Do my MTR screenshots suggest there is a problem at "US LEVEL3"?
I have a similar issue but with a 4GB KVM special VPS. HetrixTools record frequents 1-minute outages, and in the VPS logs I see many more 5-10 seconds dropouts.
I opened a support ticket, which was replied to very quickly: I'm waiting for a migration to a different node, and if that doesn't solve the issue I'll consider reinstalling the VPS.
The situation appears to be getting better. (See image below).
Bit of a shame that Racknerd's technical support can't or don't want to do a bit of networking troubleshooting.
If they had looked into the problem and said to me "One of our providers/routes is having issues", then I would have said Thank You and waited for the problem to be resolved.
Have exactly the same issue. My cloudflare tunnel is continuously disconnecting and the SSH is very laggy. Did not have time to report it, but will create a support ticket as well if the issue persists.
No. If the packet loss is only on that particular hop and doesn't carry forward, there is no issue. Take a look at this presentation for more detail.
@Peppery9 Thanks
Hi @stephen_hill -- Thank You for being our valued customer, and I'm happy to hear that things are working well at this time based on your latest update here.
Without having looked into your case yet, I would like to comment generically that networking can be a complex subject, and many factors can come into play. In this case, our support team definitely should have requested a MTR (and preferably, a bi-directional MTR) in order to better investigate where the packet loss originated from so we can narrow down the issue, so I apologize if that was not done.
If you can please send me an e-mail at [email protected] with your ticket ID or VPS IP address, I can look into the specifics of your case in further detail and work with you towards a complete/permanent resolution going forward. I'll also be happy to create a case with our upstreams accordingly if the MTR's suggest that there might be an issue on that end. In this case, it sounds like it could of been a temporary issue with one of the transit providers in the BGP blend (and perhaps it only impacted specific/certain routes and hence, our monitoring systems were not triggered), but we cannot say for certain that was the case without a MTR. I'll continue to keep a close eye on our Strasbourg network on my end just in case. We also utilize HetrixTools for external monitoring of our host nodes, and have not observed any downtime alerts recently. We're happy to share those monitoring logs with you as well for your specific host node, in the interest of full transparency and troubleshooting")
Some feedback: most likely there was some packet loss in the last 24h but my 20s health check hasn't reported me any downtime, but some spikes in latency.

Compared to OVH France

Just speculation, could've been my own network. But I have to say yesterday I noticed that SSH commands were slighly delayed and some packet loss was there forsure.
Hi @zGato -- I agree, it definitely sounds like it could of been a temporary issue with one of the transit providers in the BGP mix, so I'm with you there, though like I said, just a bit difficult to say for certain without MTR's at the time of the issue occurring (and as I'm sure any provider could resonate with, it's a bit difficult for us to create a case with upstream's without factual data/MTR's to show for).
I'm going to personally keep an extra close eye on the Strasbourg network just in case the issue returns, but I'm thinking the issue may have subsided already from what it looks like.
Migrating to a different node changed the IP address but didn't solve the network issue, reinstalling the VPS from one of the provided templates seemed to work at first, but upgrading the OS failed at the 1st reboot with an 'iscsiroot' kernel error.
Frustrated, I sent in a cancellation with 10 months remaining out of 12. @dustinc , I've been happy with the support I received, I hope you can take the following points into considerations for future improvements:
Their france location has a slightly defective network, monitored my idling giveaway VPS on hetrix for a few months and it was down for a couple of mins every few days, around 99.9% uptime. Which admittedly does not sound that bad, but I'd rather downtime be a rare disaster rather than daily
Stark contrast to the other locations I have tried - chicago and amsterdam could challenge AWS for uptime. Seems coloncrossing can do something right