


























New on LowEndTalk? Please Register and read our Community Rules.
All new Registrations are manually reviewed and approved, so a short delay after registration may occur before your account becomes active.
All new Registrations are manually reviewed and approved, so a short delay after registration may occur before your account becomes active.



Comments
My Oracle VM.Standard.A1.Flex Osaka-Japan since 391d 3hr ago

08:48:55 up 322 days, 4:17, 1 user, load average: 0.00, 0.00, 0.00
@webhosting24 vps from 2021 BF 10x10x10
14:51:55 up 512 days, 14:24, 0 users, load average: 22.54, 28.37, 29.04
ultra.cc seedbox
I miss my AWS server, it had over 1000 days of uptime
I reboot Debian with every kernel update
My toughest uptime so far
Limestone dallas
BuyVM Las Vegas from anynode refuge
Boomer host
Hosthatch SG E5 NVMe Promo from BF
My home lab server (QEMU hypervisor).
It used to my longest uptime champion until my mum accidentally shut the breaker. Failed to achieve an uptime of 1K days. This is a record from 1Month ago.
ihell@CN-JS-02:~$ uptime
22:17:40 up 991 days, 7:20, 3 users, load average: 4.71, 3.98, 3.97
DigitalOcean NY1
Network Uptime (Hetrix Tools):

High uptime is easy to achieve. However 100% network uptime from an external monitor that is harder.
Anyway a server high uptime without kernelcare that just means "I'm vulnerable as F".
A web server I have over at Linode - made me chuckle:
root@XXX~# uptime
00:49:49 up 472 days, 1:53, 2 users, load average: 2.05, 1.90, 1.99
Monitor by Hetrixtools

make a prayer today, may God help you
Tip: if you're using the HetrixTools server agent, you can easily see which servers have the most uptime by sorting your uptime monitors by System Uptime:
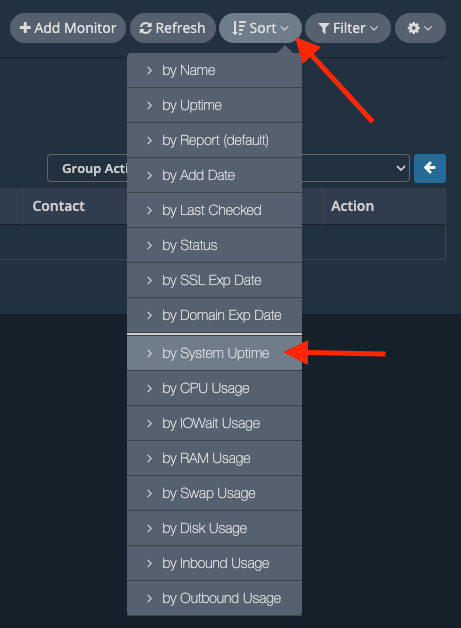
Cheers.
MyW webserver:
[root@server ~]# uptime
18:27:59 up 1250 days, 17:51, 1 user, load average: 0.29, 0.42, 0.41
wde1 server:
[root@wde1 ~]# uptime
19:28:12 up 701 days, 23:38, 2 users, load average: 6.50, 7.87, 7.88
wsg1 server:
[root@wsg1 ~]# uptime
02:28:40 up 380 days, 17:39, 1 user, load average: 12.70, 13.38, 13.65
dns1 server:
[root@dns1 ~]# uptime
19:30:21 up 371 days, 21:33, 1 user, load average: 0.20, 0.22, 0.19
dns2 server:
[root@dns2 ~]# uptime
19:30:41 up 371 days, 21:33, 1 user, load average: 0.16, 0.11, 0.12
I reboot server everytime it’s unreachable
Upcloud NYC
root@nice:~# uptime 03:54:44 up 636 days, 8:53, 1 user, load average: 0.06, 0.03, 0.00We have some servers restart for update. This uptime from virtualizor panel.












 "")
"")
One of our Debian server
Some of my servers had multi-year uptimes, but not since Summer. I have been doing a lot of trials and testing, reinstalling operating systems, etc. Now my servers have new configurations and short uptimes.
NexusBytes 🇸🇬
I have a customer with a very very old production server, running debian 4 (etch), since more than 4500 days.... And it's directly connected to internet!
Story behind it is they tried to patch it when heartbleed went out... This fucked out completely the vm ... But software was still running. So they decided to let it run until it die and replace the whole software when it will happen.... The thing is that never happened.... And until today it's still up and running!
I have been wondering, shouldn't machines be rebooted after certain updates? I love to see high uptime but wondering if it's misleading somewhat in other avenues
Remember the bug in Windows 95 and Windows 98 that caused them to crash (BSOD) after running for only 49.7 days? Those versions of Windows were so unstable and crashed so often that it took four years before they found and fixed the bug.
you guys didn't install critical linux update?
What makes you say long uptimes mean no updates?