


























All new Registrations are manually reviewed and approved, so a short delay after registration may occur before your account becomes active.
Production server | What the heck?
 FlorinMarian
Member, Host Rep
FlorinMarian
Member, Host Rep
A new day, a new post.
I woke up this morning with 5 tickets in which I was told that the KVM servers were moving deplorably and later I had to find out why (see the screenshots).
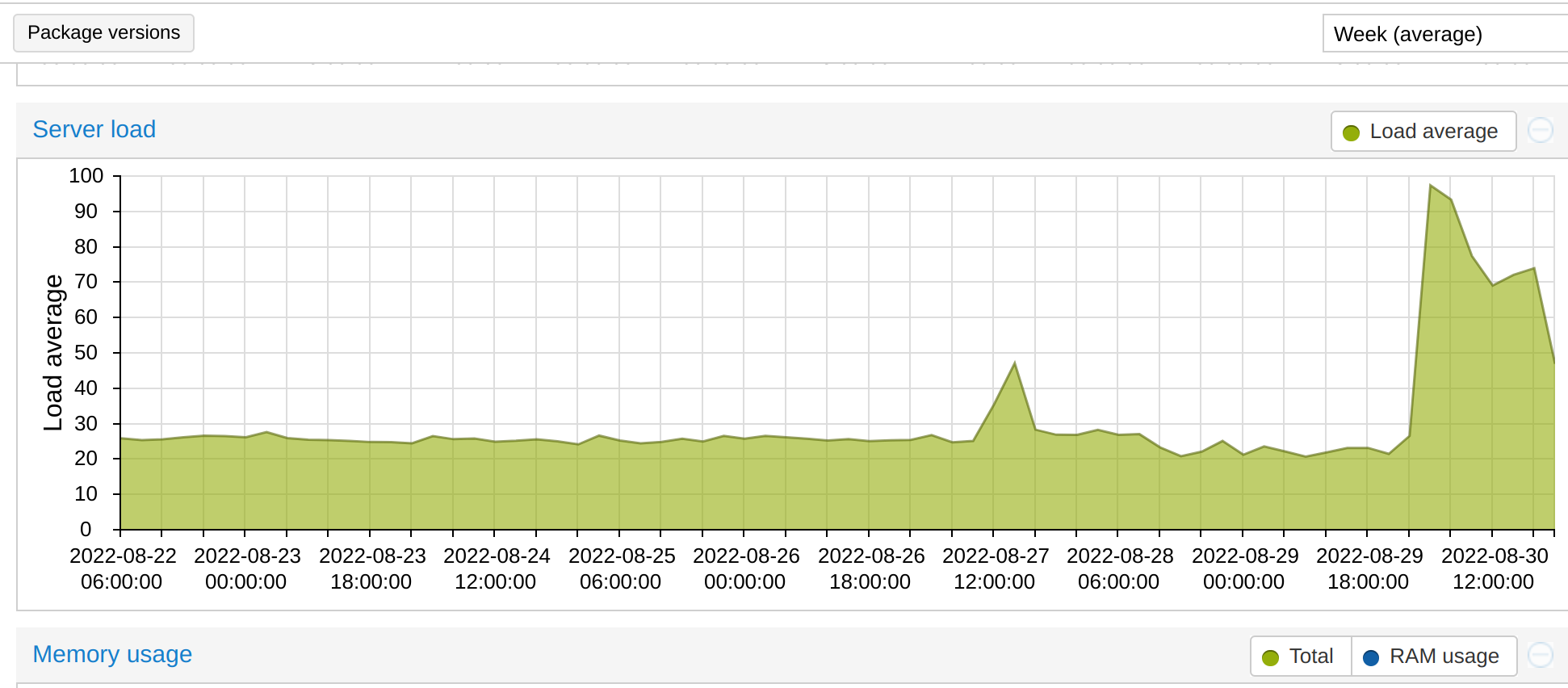
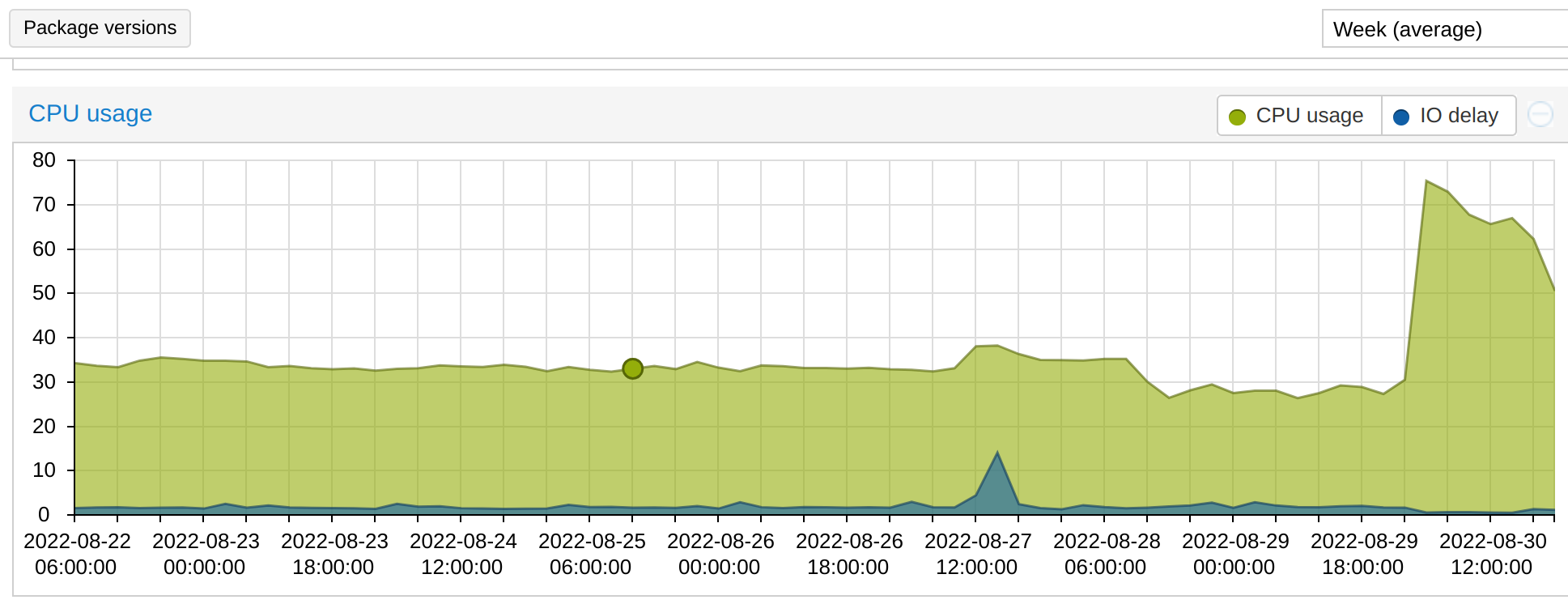
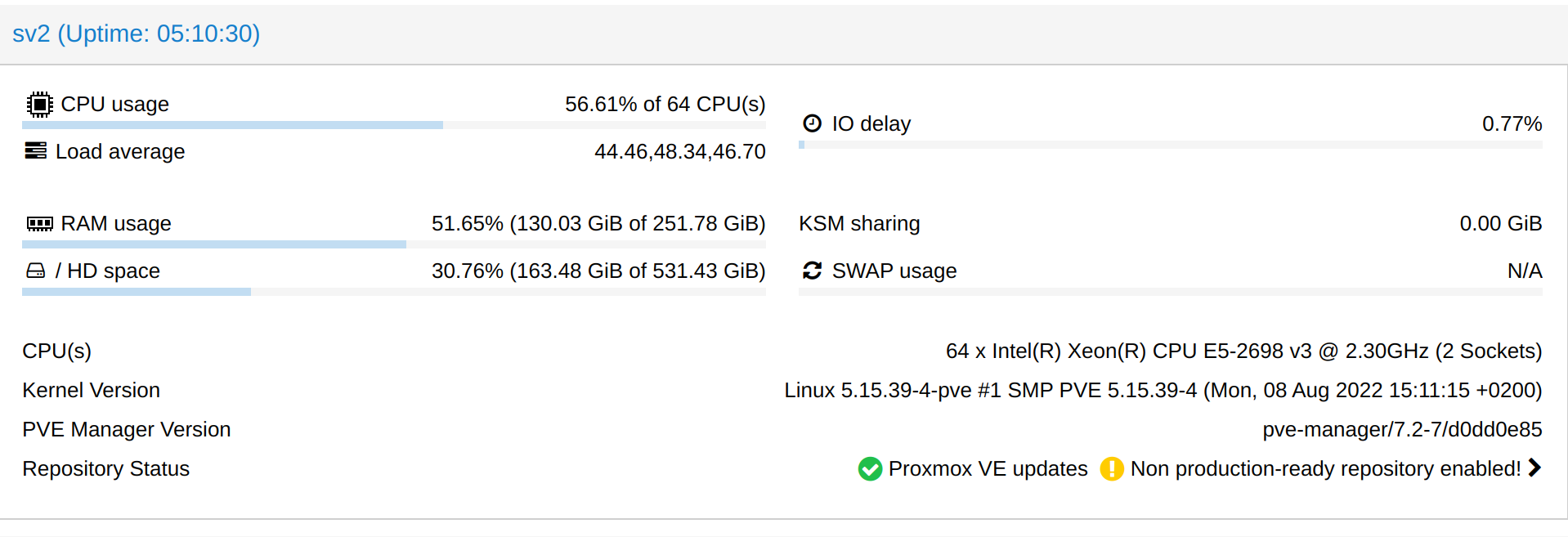
The big problem is that I was at the office (at work) all day and then I traveled by train, going back home only in the morning, in about 10 hours.
I know it is not ethical, professional, inspirational and well seen, but in order to solve the situation as quickly as possible tomorrow, I will tell you what I have already done and I did not manage to find the source of this problem:
1. I tested the RAM memory (nothing abnormal)
2. I checked the values in "smartctl" for each individual disk, there is no error on any of them
3. I checked the health status reported by proxmox for each ZFS pool, nothing abnormal there either.
4. I checked the temperature of the processors, nothing abnormal (below 60 degrees Celsius)
Any idea is welcome. (I try to impact customer services as little as possible, being an already critical situation)
Thank you!

Comments
Did you looked at the list of processes?
powersave strikes back.
Yes, nothing abnormal.
I found out that most of VMs increased their usage at the same time, going from idle to 50-100%. Tried to figure out a pattern like a specific zfs pool but wasn't the case.
Performance is already on.
How is the IO overall?
Quite low.
Under 20Mbps according to iotop.
Looking for info at proxmox forum,
one solution was to restart:
pvestatd and udev
daily.
Other just attributed the issue to a CPU hardware, replacing the CPU's fixed the problem
We had today a node reboot but this didn't changed anything.
Tomorrow when I'll get home, I'll take care of it.
Thank you for your time!
Is this a soft raid? Could be a storage issue, maybe something not detected with smartctl. For example soft raid degradation, syncing, IF I'm not mistaken, soft raid could use the CPU intensively. Specially if HDD?
Good morning!
With all VMs turned off, I discovered a rather dubious thing, namely that with only one VM turned on (regardless of whether we are talking about an SSD or HDD pool), the benchmark no longer displays a few GB but no more than 400MB read/write . In conclusion, for some reason, the server no longer uses ZFS cache, even if the minimum/maximum values remained the same (several tens of GB).
SSD pool:
HDD pool:
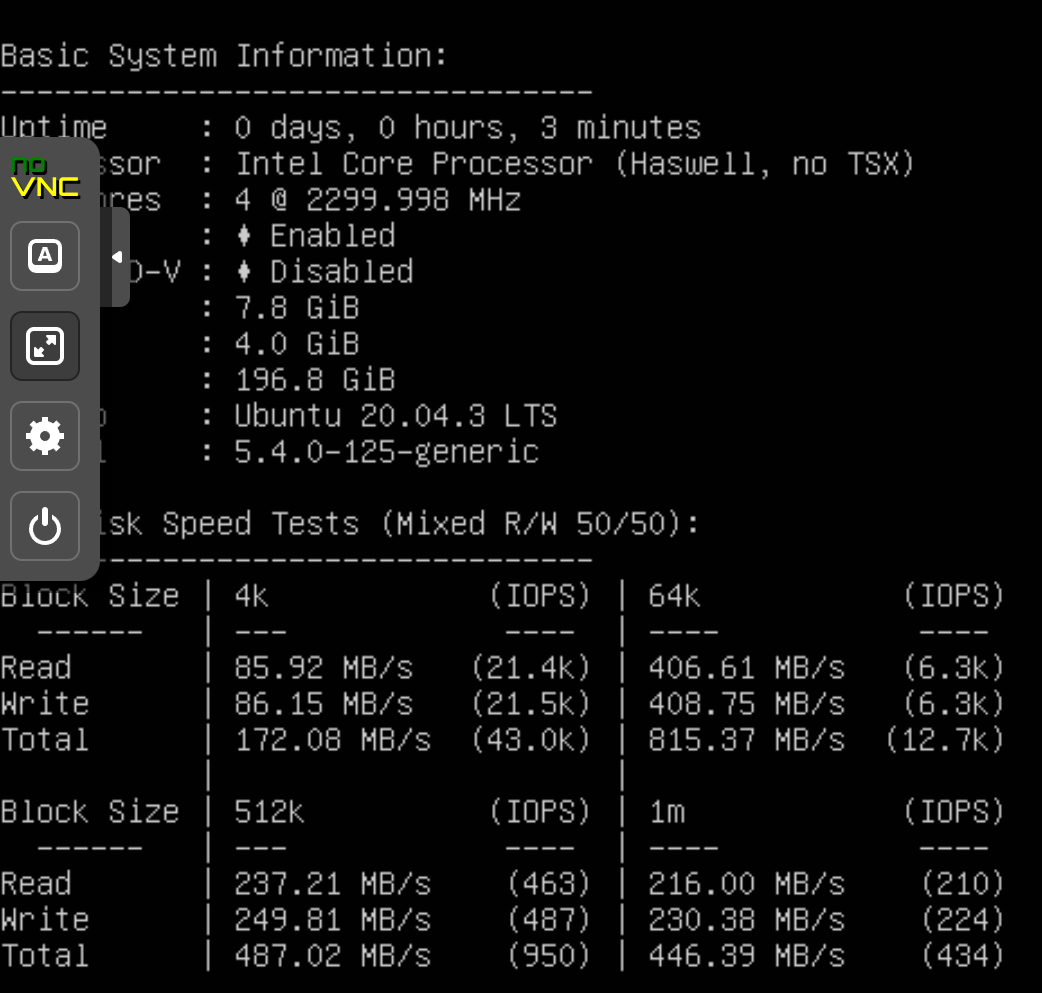
What model of ssds does the system have?
do you guys here get paid for the support you offer for his hosting company ?
Proxmox itself running on Samsung 860 EVO and customers VMs Samsung PM893 1.92TB.
But those like you who search on google for solutions to their problems and find solutions following the discussions of others, are they paid well?
Its the provider asking for guidance. Im also interested what could cause this so its a good topic.
Did you look at each virtual machines graph to see if any of them used a lot of CPU starting a few days ago (week graph)
The whole problem appeared around 01:30 UTC+3, a day ago.
Among the affected machines (more than 50% being affected) there is also one of my git servers which both before the problem appeared and after it was idling and suddenly the permanent consumption of the CPU had reached 50-100%, without had processes that consume those resources.
It is clear to me after doing the same benchmark on the same VM that the storage is 20-30 times slower, ZFS cache no longer having an effect but even without it, I have too few iops. (several hundred, being the only VM that consumes storage)
PM893 probably won't get as bad, but the evos will go to a crippling level of performance if you have allocated the whole drive and don't do trim passthrough (often not supported in software caching).
To confirm or rule out assuming you've got a raid configuration for your SSD caching, drop a single SSD from the array and secure erase it; once it's done - readd to the array. Then do the other drive.
Clearly someone has launched YABS on cron. On a serious note: you deploying ZFS? If yes, read documentation on proper debug. Probably scrub? Out of cache? It is your job to do.
We have disk pools from 4 different categories:
All are slow and currently I suspect that the problem may be with the "LSI SAS 9305-16i HBA - Full Height PCIe-x8 SAS Controller" card, which would be to blame.
No VMs running, barely a reboot, 99% of RAM free and we don't have more than 450Mb RW via ZFS, and before we used to reach 10GB using the same configuration.
Hmmmm, that actually sounds a little familiar with the situation I have on my home router, which is the only place I run proxmox. About every 4-5 days one of the Linux guests at random starts consuming 100% of its CPU, still responds to pings but I can't ssh into it any longer presumably because of the 100% CPU usage. I've tried all the combinations of host type, video type, HDD type I can find, but it still happens all the time. Interestingly, the pfSense which is a BSD guess doesn't have these same issues (and yes, I've tried the exact same config as that for my Linux guests and they still failed with the 100% CPU).
I've not had this issue with VMs anywhere else, but I use qemu/libvirt directly for all of those, so my suspicion is that it's some weird proxmox bug, but as it also uses qemu/libvirt under the hood, I'm not sure what it could be. So, I then put it down to just a hardware issue (this is the only VM host I have running on an Intel Atom) and live with rebooting those guests whenever I notice one is stuck.
But it might be worth checking if you're up-to-date with proxmox patches and/or try downgrading if you've recently upgraded it. My proxmox that I'm having issues with has been running just under 2 months.
I've read that ZFS, whilst being incredibly good in the normal case, can be quite hard to debug at times when something goes wrong. If you're new to ZFS, it's almost certainly considering this as the suspect more and trying to find out exactly what it's doing.
I ask mostly support if i have a problem...
This is the best time to buy proxmox subscription
Check iptraf-ng to see if anyone running UDP flood
No UDP ports are open with all VMs stopped and also
iotopwon't report any abnormal RW activity.Why are you using ZFS with HW RAID (and how to be honest?) when even ZFS advises against it ?
Mentally strong people disable RAID and use separate ext4 partition on each disk.
I don't use HW RAID configuration.
Mentally strong people run RAID 0 (striped) with many drives and no backup, right? :-o
IOWAIT increases if storage issue. IODELAY (IOWait) has remained low.
Sounds a bit like some chip is overheating, likely the motherboard chipset or LSI controller. Are you able to turn of the host for say 30minutes to let it cool for a few moments? do you have local on-site access?
I would remove the LSI and motherboard chipset heatsinks, replace paste and try again then.
We've seen a lot of peculiar performance issues when motherboard chipset overheats, but i don't recall an issue with LSI HBAs needing repasting.
Then again, might just be ZFS. We've had nothing but trouble with ZFS tbh. Tho, gave it a try again just few weeks ago and had some very interesting and unexpected benchmark results. Perhaps ZFS is finally maturing.