



























New on LowEndTalk? Please Register and read our Community Rules.
All new Registrations are manually reviewed and approved, so a short delay after registration may occur before your account becomes active.
All new Registrations are manually reviewed and approved, so a short delay after registration may occur before your account becomes active.
★ VirMach ★ RYZEN ★ NVMe ★★ $8.88/YR- 384MB ★★ $21.85/YR- 2.5GB ★ Instant ★ Japan Pre-order ★ & More
This discussion has been closed.

Comments
now,most of the time, it's 50±50ms.
it seems like something wrong on node 35's network, extremely high latency.
Dude, you're probably overcomplicating things again. As a long-time user of Virmach since 2017, I'd say that's not the case. In fact, most of the people in this thread don't mean to question in any way that you're not doing everything you can to try to fix the problem, rather, I precisely sense that you're working very hard on this and recognize the effective measures all of you are taking to prevent further deterioration of the Tokyo area node, otherwise I don't think I would be here so much to say so much and just go ahead and request a refund.
I don't mean to accuse anyone here, but the lack of a good communication channel ealier (Now you have built a specific web page for updating the latest news. That's commendable.) and the fact that people's expectations for the Tokyo pre-sale were too far off from the reality did lead to what seemed to be a bit of an emotional and irrational pre-sale.
I believe that people living in the Asia Pacific region should be quite interested in the Tokyo pre-sale, as few providers will be willing to offer products in this location on the lower end of the lineup, which is usually a high-end gamer's playground. Not to mention the fact that after the test IP was given in the back, the routing to China was the better IIJ [AS2497] instead of the usual NTT [AS2914], which is exciting and makes people have an unrealistic fantasy about this pre-sale - it seems that many have forgotten that the offer they paid could not afford their illusions and that everything was realistic.
Another thing you are missing is that some people, as far as I know, will mistakenly believe that once all the equipment is successfully cleared somewhere, it will be ready to go live in the server room immediately.
For many people, participating in this pre-sale is, in itself, a desire to buy a more affordable Tokyo-area VPS. I know a lot of friends who are not too interested in migrating because they have already purchased many San Jose, Los Angeles, and Seattle-area VPSs.
Don't worry too much, you are doing just fine now aren't you? Everything is progressing in a good direction and I will wait patiently for all the VPS in Tokyo area to be up and running. If you are worried that the latest news update page due to the lack of Chinese version, Google translation will lead to some translation errors will result in disagreement, I may be able to help by providing you with the Chinese version of the translation.
There is an network problem of gateway now.
Just putting this out here ...
## add 512MB swap file ##
Or the one liner (same as above) ...
dd if=/dev/zero of=/mnt/swapfile bs=1024 count=512k && chmod 600 /mnt/swapfile && mkswap /mnt/swapfile && swapon /mnt/swapfile && echo '/mnt/swapfile swap swap defaults 0 0' >> /etc/fstablibvirt killed the process because it crashed, since it ran out of memory.
Such a nice day.When I woke up, I was migrated out of the original node, but the new one started "boom boom ".
@VirMach Sleep, only a good state can deal with problems more efficiently!Good luck.
34 node network problems
I dealt with IP stealing on all nodes, I had to re-arm the solution against this and reloaded ebtables. This caused most nodes to go into high interrupts.
It looks like either some of these got hacked already from weak passwords or just some abusive customer(s) were taking advantage of that. Anyway, I've had this happen before in some rare cases in the past where someone was hosting a traffic relay service or perhaps a botnet, and when for example the VPS is suspended, there's either broadcast radiation or the thousands of IP addresses previously involved still try to make a connection with the VPS and it ends up essentially ending up similar to a denial of service attack, and we end up with a tight packet loop. Anyway, I'm sure I could try to fix it without a reboot but at this point a reboot would be best. It'll also help me identify problematic VMs on all nodes as the logs will be more tightly packed together.
It'd be interesting if it's somehow more directly related to ebtables as I did technically reload that first on TYOC040 but at that point, I did everything first on TYOC040.
Here's what I mean, here's an overlap graph, and the moment CPU and network shift is when high packets of traffic could no longer reach that virtual adapter.
This might actually be it. I'm going to look into it further.
If everyone's network just got better then I'm going to have to have a little talk with SolusVM. That was a rhetorical question. Oh wait it wasn't even a question.
Okay, yea, it looks like this is some kind of conflict with SolusVM's ARP attack protection feature and whatever we're doing on our end. I have a headache, I'll check on that later and I'm probably leaving for a couple hours. I'm going to get more creations going now.
something is happening on node 40. network is coming back
Hey boss , my vps is still suspension. The reason is "OS is causing overloading. Contact Priority Support." , I have submitted a ticket yesterday.But I have received our "[Important][TYOC040] Your service may be recreated
" email.So I cancel the ticket. what should I do now?
@VirMach - Just an FYI on Node 39 there was some jitter between ~1:20PM and ~4:20PM PDT, which has cleared up now. The time on the graph below is based on CDT (2 hours ahead of you)
Larger image here
Network graph
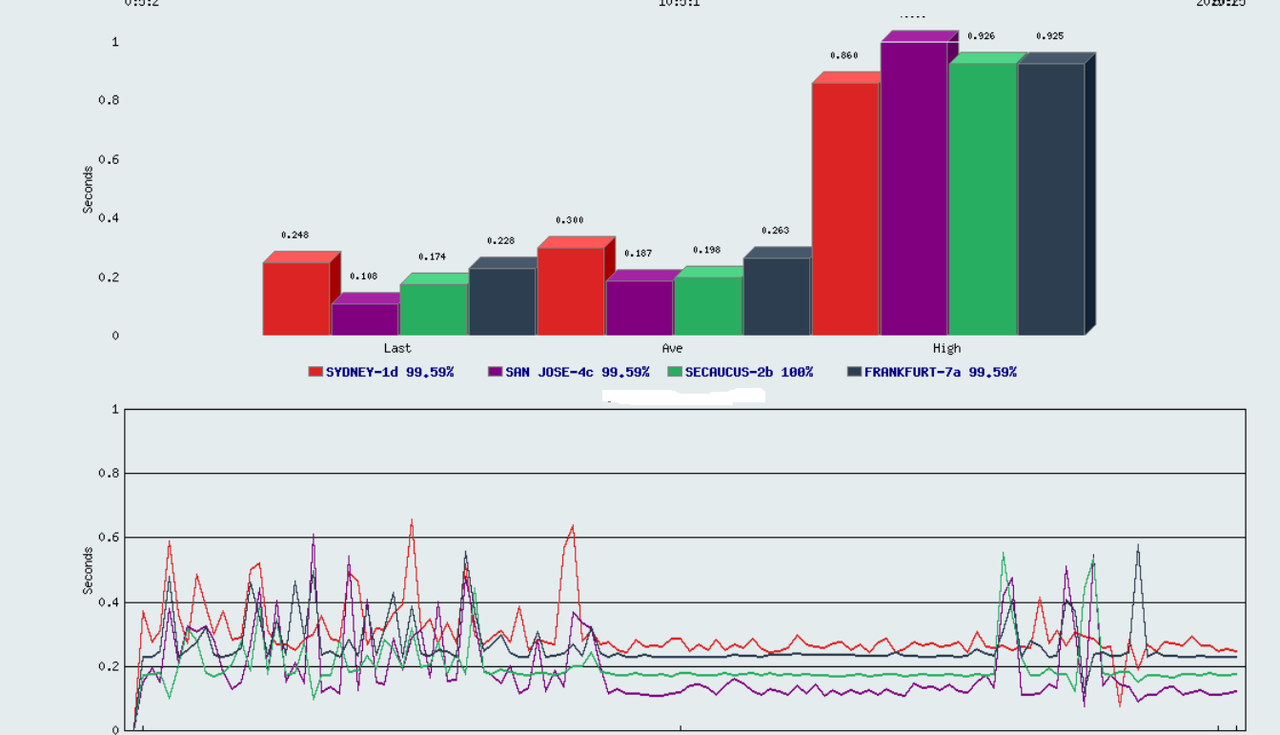
Larger image here
yes,The network has been restored.
Sorry, these were going to be included in the recreations but I forgot to process them. I'm going to bring these back online now since they didn't get included in the recreations. Yours was suspended before the email.
before i reinstalled, i set up 2g swap
same result
Yeah I saw the jitter on all nodes too. That timing is correlated with me enabling those options I think but I also noticed that it cleared up a little earlier than just now when I lifted all of them. Something else is probably going on too.
Yeah, from my experience if it goes OOM on apt-get stuff the swap won't help, you need more RAM. That's just a guess though, I'm not very experienced with running stuff on low RAM as I have access to a lot of free high RAM virtual servers due to my line of work.
upgraded from debian10 to debian11 with apt, not shutdown
why?
Probably because it didn't run out of memory then, but it runs out of memory now. I assume upgrading from Debian 10 to 11 means a lot of apps got updated too, and now those use more memory, so when you're now using Debian 11 and also trying to run whatever you're trying to run on top of that finally made it too much.
You're actually right today, but I just realized I haven't had my coffee today and that's the problem!
Okay guys, stagger creation script starting back up. I'll focus it on the two new nodes for now until they fill and then go over one more layer on all the nodes at the end.
=
Maybe once or twice per week I get tired and can't think too well and I completely forget that I need coffee. I guess it reaches the point of being in such a bad state that I forget to even get coffee.
I feel awful all day, and headache etc as you just mentioned nd for some reason I don't even remember the coffee. It's not like any other type of addiction (like cigarettes) where your body would remind you that you need to have it. Well at least not mine.
I don't think it's necessarily a OOM problem. I've been using a Virmach VPS with only 256MB RAM and 256MB swap on a KVM node for sometime now. It had Debian 9 initially installed through template and is running debian 11 installed via netboot.xyz. Never had any issue with apt or even aptitude although otherwise it's never heavily loaded either.
Maybe it has something to do with the SSD still? Or the template from SolusVM?
Well it's important to remember that "Debian 11" can mean a lot of different things. The other guy obviously isn't just running Debian 11 at its full minimalistic installation with absolutely nothing else, I assume? So it'd be Debian 10 + the upgrade of Debian 10 to Debian 11, maybe other things were added, and maybe something else is also running in the background.
At least those are just my default assumptions, otherwise they're a true idler.
(edit) Absolutely nothing to do with the SSD though, it's not that type of error and it's specifically OOM with the RAM amount as like 440MB or so which is what it gets cut off at for a 384MB plan.
root@AAA:~# apt update
Hit:1 https://deb.debian.org/debian bullseye InRelease
Get:2 https://deb.debian.org/debian bullseye-updates InRelease [39.4 kB]
Hit:3 https://security.debian.org/debian-security bullseye-security InRelease
Get:4 https://deb.debian.org/debian bullseye-backports InRelease [44.2 kB]
Hit:5 http://nginx.org/packages/debian bullseye InRelease
Get:6 https://deb.debian.org/debian bullseye-proposed-updates InRelease [44.6 kB]
Fetched 128 kB in 1s (195 kB/s)
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
All packages are up to date.
root@AAA:~# apt upgrade
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
Calculating upgrade... Done
0 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.
root@AAA:~# apt autoclean
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
root@AAA:~# apt autoclean
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
root@AAA:~# apt autoclean
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
root@AAA:~# apt clean
root@AAA:~# top
top - 09:52:35 up 6:33, 1 user, load average: 0.00, 0.00, 0.00
Tasks: 70 total, 2 running, 68 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.0 sy, 0.0 ni, 93.8 id, 0.3 wa, 0.0 hi, 2.9 si, 2.9 st
MiB Mem : 348.5 total, 49.9 free, 55.3 used, 243.4 buff/cache
MiB Swap: 256.0 total, 256.0 free, 0.0 used. 282.8 avail Mem
i also have several vps, even 256 ovz
same with debian11, no oom problems
i can't understand...
Let me get my coffee and I'll spin up Debian 10, upgrade it to 11, on the same node, using the same template, and see if I can reproduce that. If I do reproduce it I'll provide some feedback on what can maybe be done.